Documents
Documents
The Documents page contains key information about an existing document set, its processing lifecycle and configuration parameters. You can view/edit document set details, OCR configuration parameters, and manage documents. To view the document set details, you need to be granted DocumentSet-READ permission. See Role Permissions.
To access Documents, you need to:
- Navigate to the Document Sets page.
- Click on the corresponding Document Set Name.
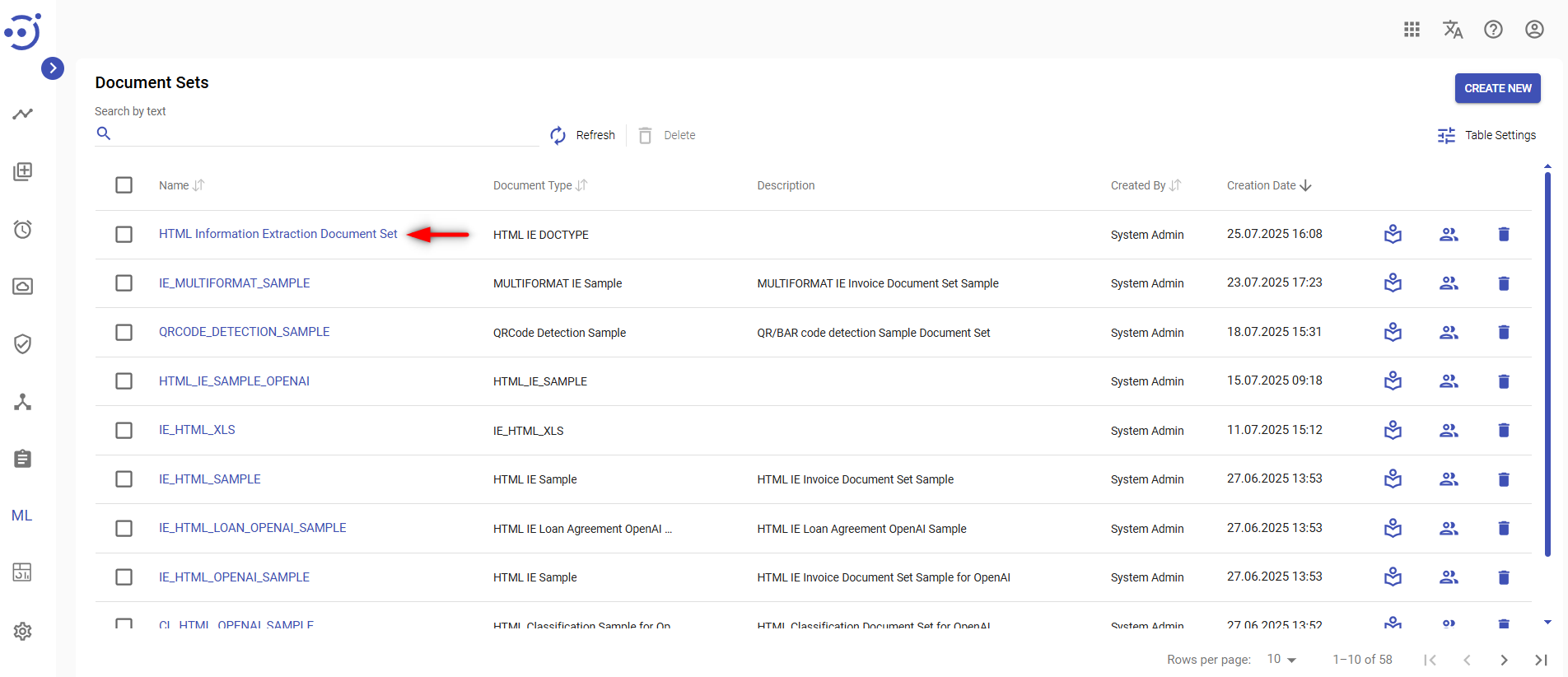
To manage documents within an existing document set click Documents tab.
Documents Overview
The Documents tab contains key information about all documents within a particular document set, their statuses as well as document inputs and outputs.
You can manage the documents using control buttons. To access the documents of a particular document set, you need to be granted DocumentSet-READ permission. See Role Permissions.
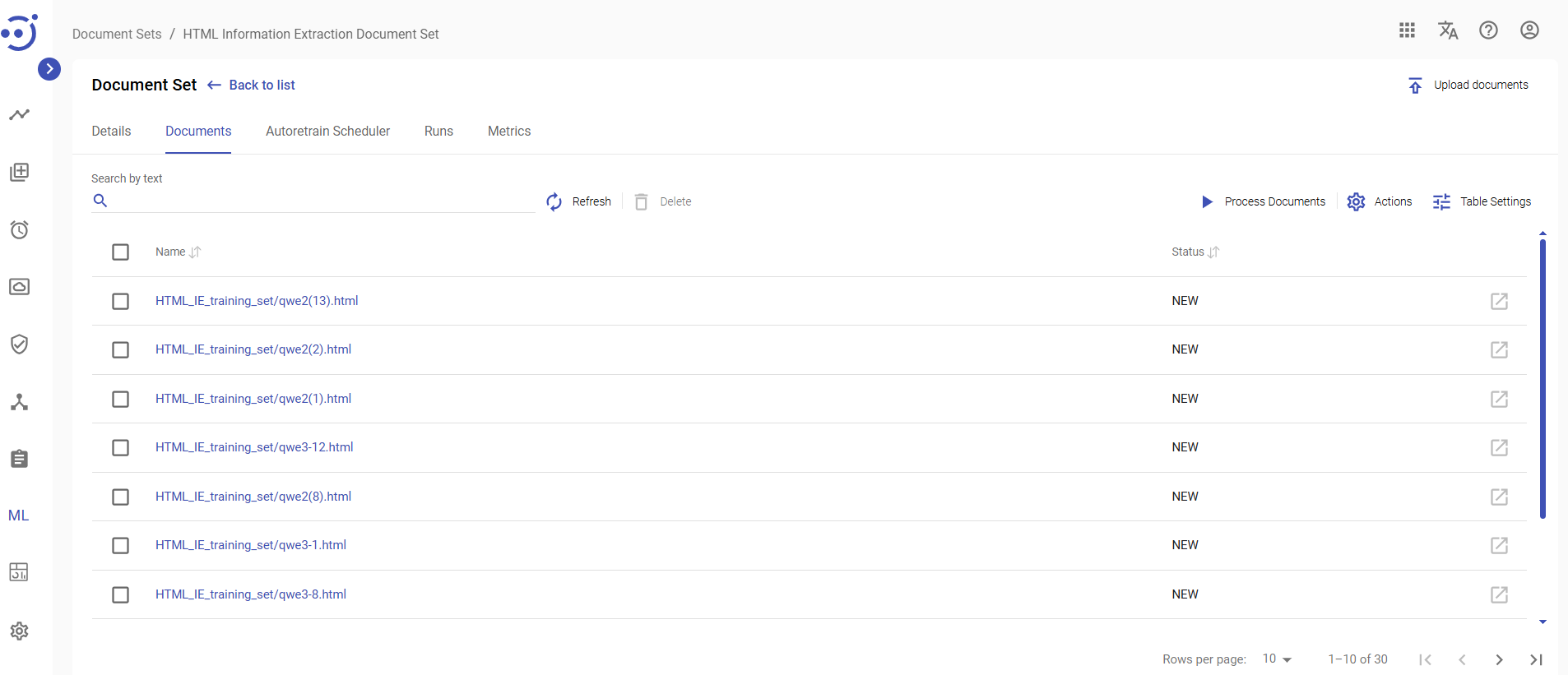
Columns Description
- Name - the name of a document within a document set.
- Status - the current status of the document processing.
Control icons
- Upload documents - to upload/add documents to an existing document set. Required permission: DocumentSet-UPDATE.
- Refresh - to pull the latest updates from the server.
- Delete - to delete documents from a document set. Required Permission: DocumentSet-DELETE.
- Process Documents - to access dropdown run controls of documents:
- Preprocess - to trigger document processor and prepare document input;
- Execute Model - to launch tagging by ML model;
- Move Model to Human - create a Human Task to review/edit (improve) ML model results;
- Send to Workspace - create a Human Task for tagging;
- Generate Model Report - generate statistics report of ML model results (both model and human output results are required to generate statistics report);
- Prepare training set - prepare document set for training.
- Clean up - delete documents from document set and the corresponding S3 folder, delete the corresponding S3 folder.
Actions
The run can be done for all documents if no documents are marked with checkmarks, or selected documents if there are marked with checkmarks documents. Required Permission: DocumentSet-ACTION.
- Actions - to access dropdown actions to manage all documents of a document set:
- Export Document Set Data - to store all files from File Storage folder into files of .zip and export records into a .csv;
- Clear Document Set - to delete all documents from the document set and the corresponding S3 folder;
- Train Model - to launch model training;
- Import Document Set Data - to store (with override) all files from .zip into File Storage, add new records into a datastore using records.csv from .zip, replace all File Storage references with new paths;
- Autoretrain - to launch autoretrain process.
- Open Automation Process Runs - to open document processor Runs page. See Automation Process Run.
- Synchronize Metadata Columns - to bring columns from More Section to Documents. See Document Types.
- Indexes - to create or delete indexes.
- Columns - to create or delete columns.
- Open Document - to view/edit human and model output of a document. Required Permission: DocumentSet-READ.
Table Settings
Table settings allow you to manage the table view. Click the icon ![]() to start working with the table settings. The table settings can be managed with the following buttons:
to start working with the table settings. The table settings can be managed with the following buttons:
- Advanced filter - to switch the advanced filters for the columns.
- Columns Display - to select the columns that will be displayed in the table.
- Apply - to apply the changes made to the table settings.
- Сancel - to cancel the last actions with the table settings.
Filter by text
Filtering allows you to search the documents by its Name and Status.
Advanced filters by columns
Advanced Filter allows you to extract a list from a table with predefined criteria. Click the icon ![]() to start working with the advanced filter. The advanced filters can be managed with the following buttons:
to start working with the advanced filter. The advanced filters can be managed with the following buttons:
- Clear filter - to reset all the proposed advanced filter criteria for the column.
- Сancel - to cancel the last actions with the proposed criteria for the column.
Apply - to filter the table according to the proposed criteria for the column.
Sorting
Ascending/descending sorting is allowed for the Name column and metadata columns.
Grouping
Grouping is allowed for the Status column.
Manage Documents
Upload Documents to a Document Set
To add documents to an existing document set, you need to:
- Navigate to the Documents.
- Click Upload documents.
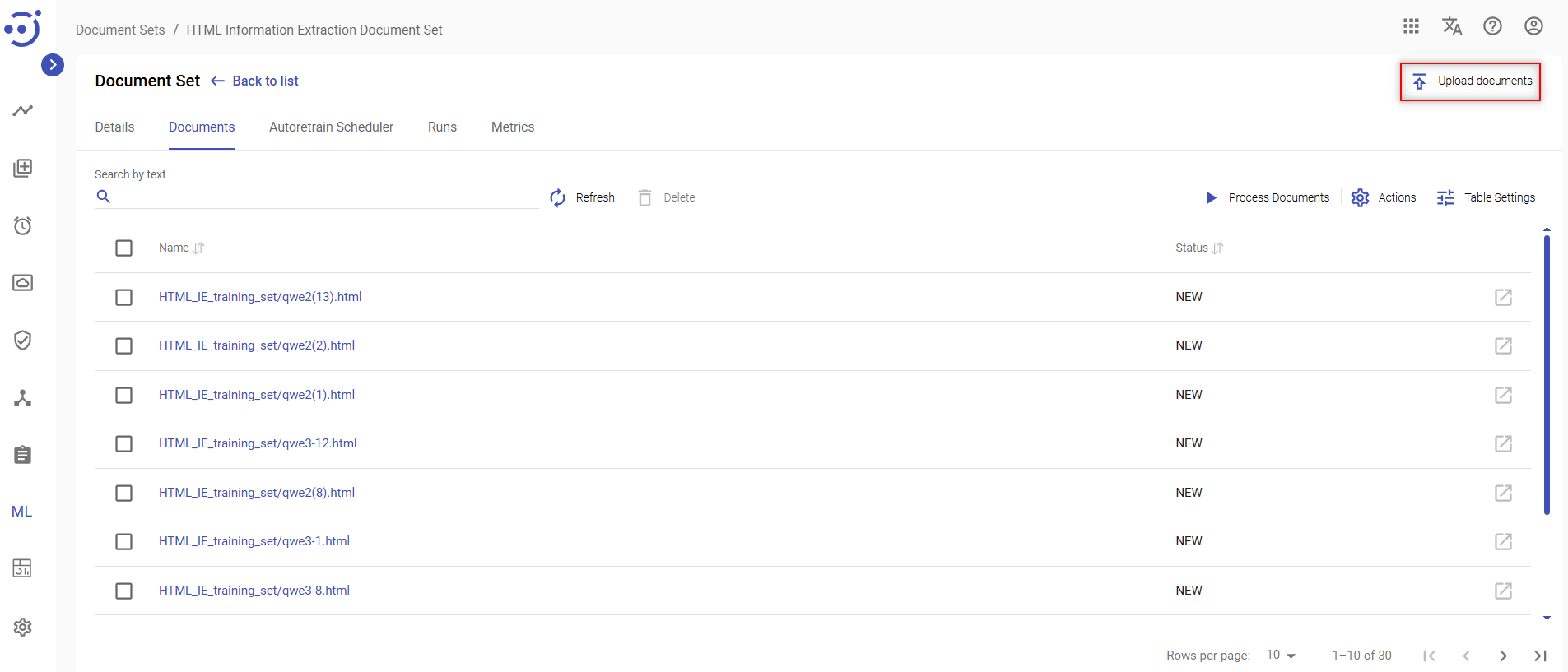
- In the pop-up window click ADD button to upload a .zip file with documents.
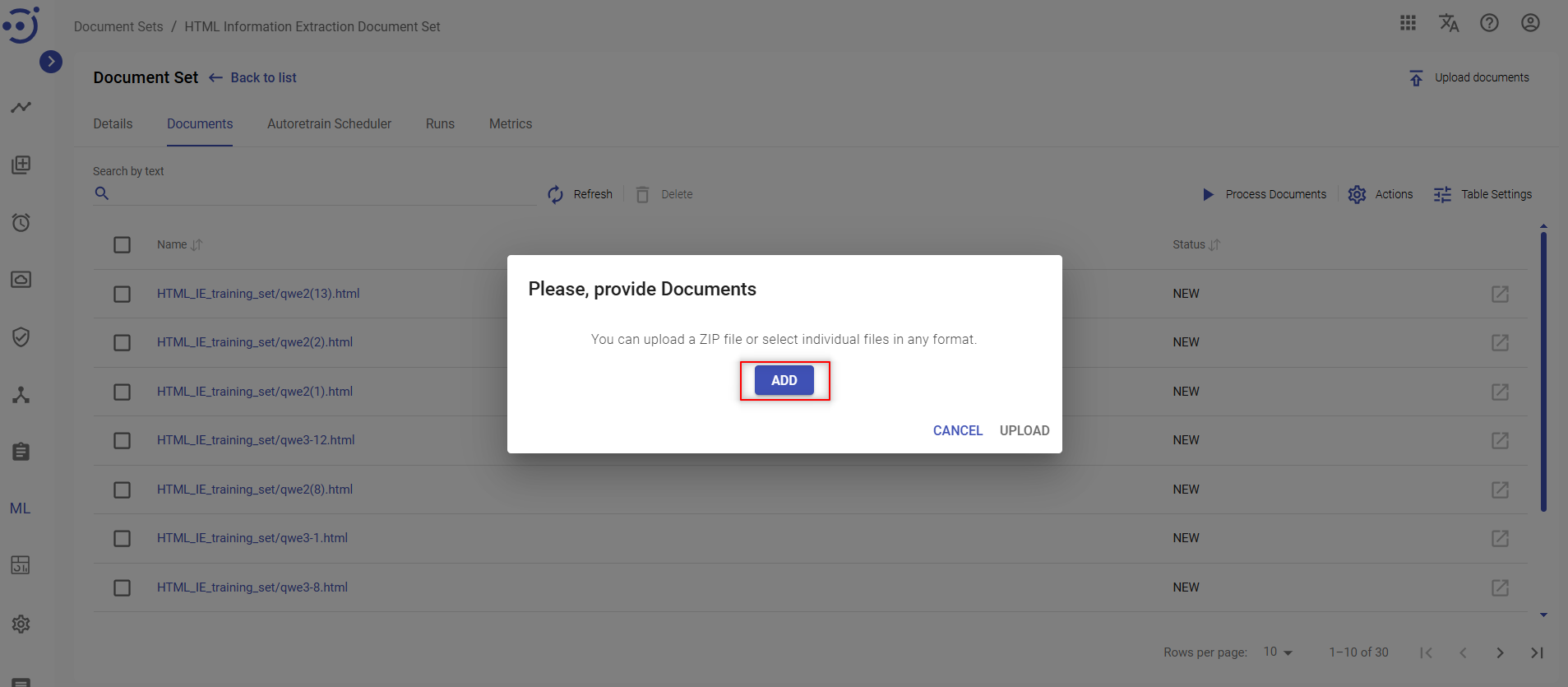
- A file explorer window is displayed. Select a .zip file to be uploaded into the document set and click Open.
- Click UPLOAD. The documents from the .zip file are added to the document set.
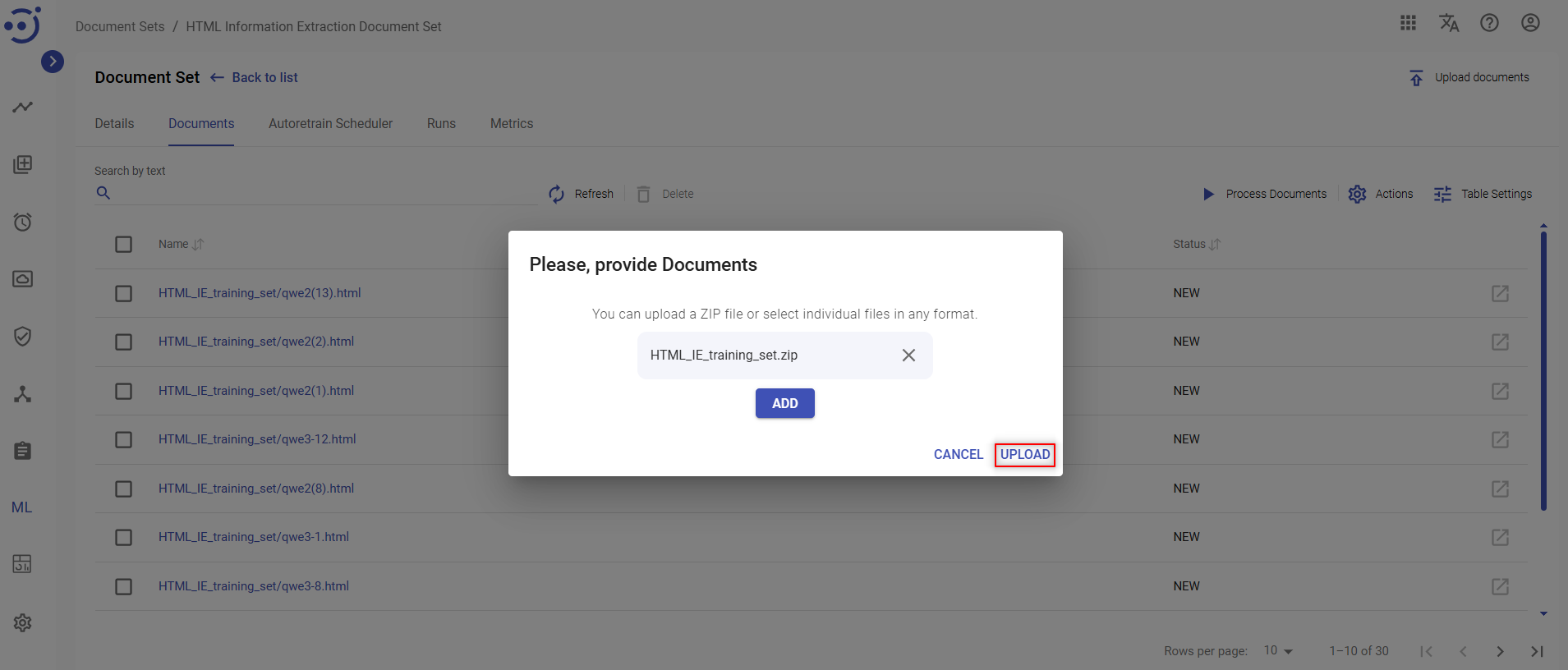
To upload documents to an existing document set, you need to be granted DocumentSet-UPDATE permission. See Role Permissions.
View/Edit Document Details
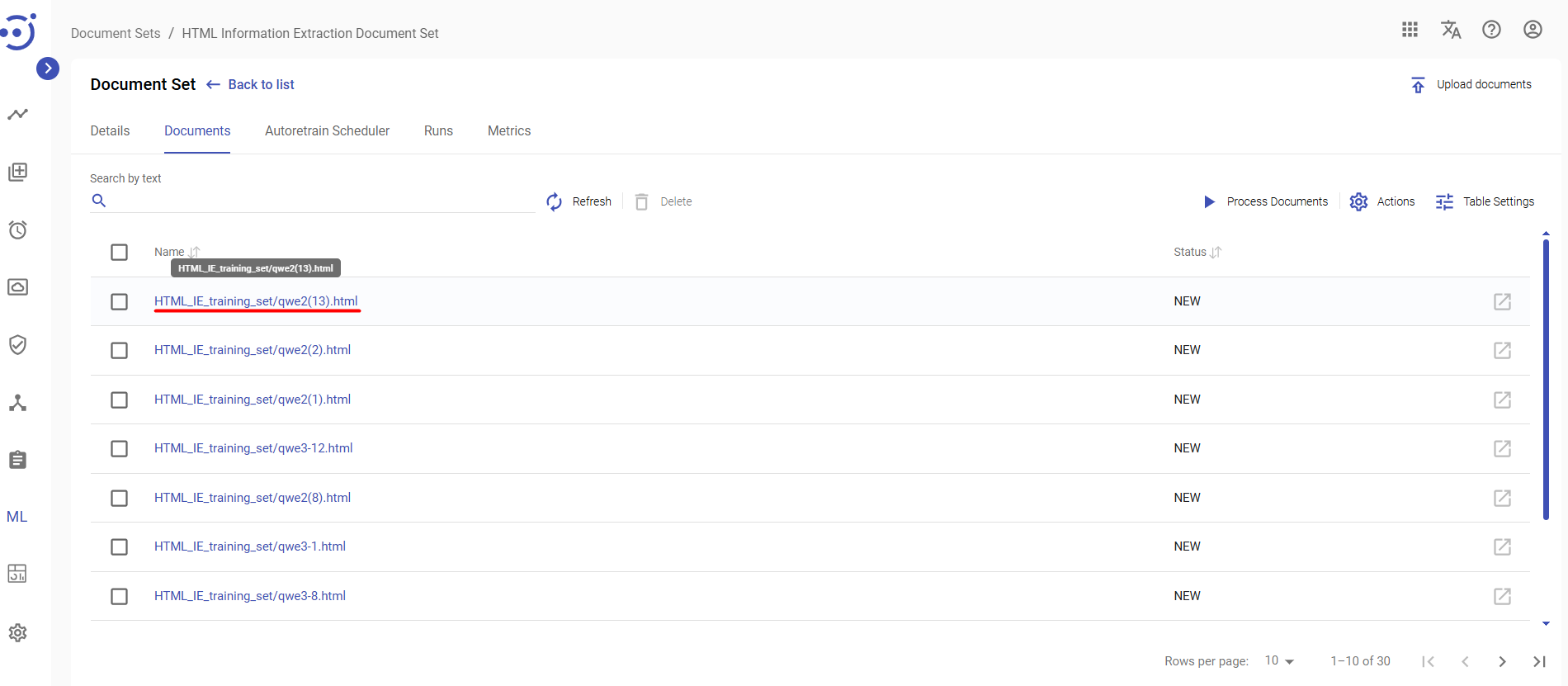
To view key information about a document click on the row with the name of the corresponding document. Uneditable Document Details panel is displayed on the right.
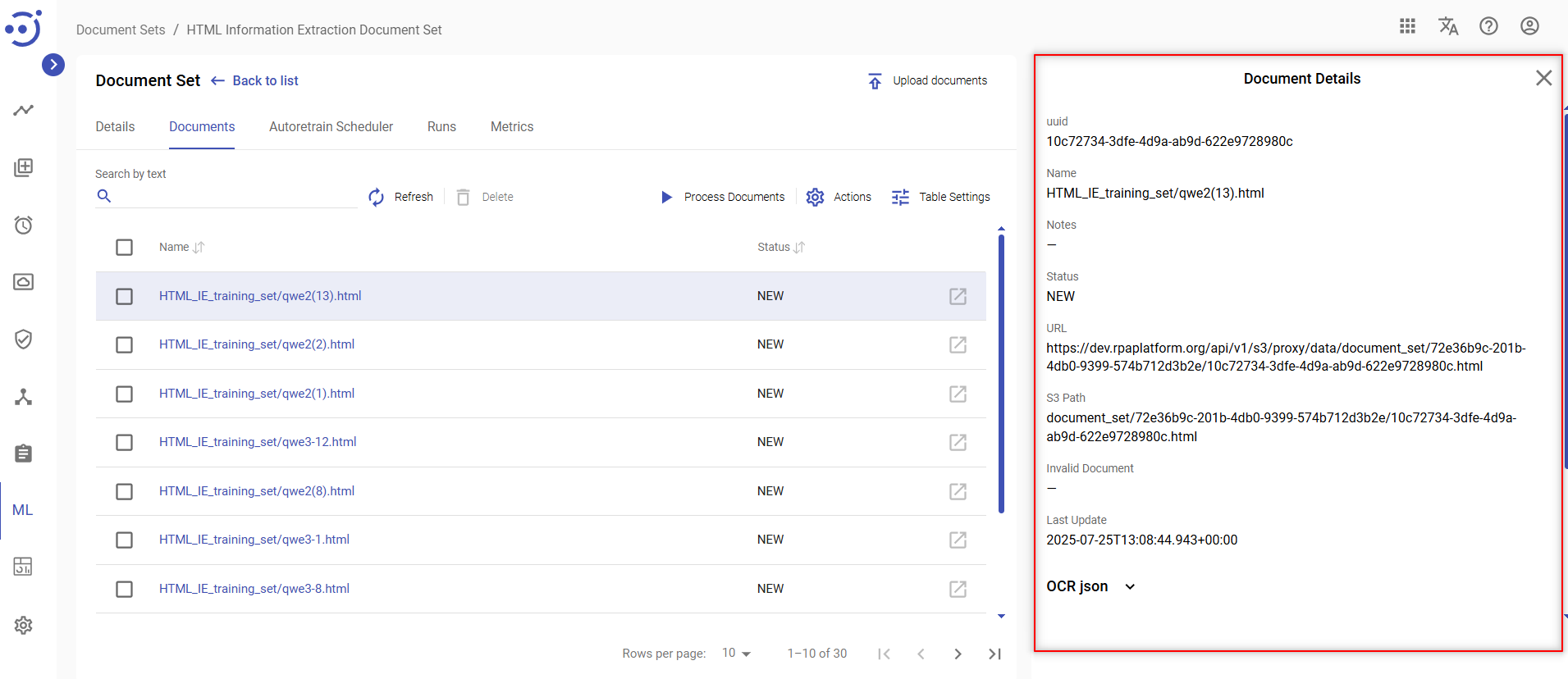
To view/edit key information about a document click on the name of the corresponding document.
You can view/edit the following information about a document in the opened Document Details window:
- uuid – the document unique identifier;
- Name – the name of a document;
- Notes – the notes on a document;
- Status – the current status of a document processing;
- URL – the document url;
- S3 Path – the document path on File Storage;
- OCR json – the result of OCR document conversion in json format;
- Document Input – generated as a result of ‘Preprocess’ action that triggers the document processor and prepares input data for Human Tasks and ML;
- Human Output – generated as a result of tagging a document via Human Task;
- Model Output – generated as a result of ML model processing of a document;
- Autotraining json – autotraining tags in JSON format;
- Invalid Document – a field that is checked by the user if the document is not suitable for further processing;
- Last Update – the last moment in time when a document was updated in yyyy-MM-dd HH:mm:ss.SSS format.
When a document is new, OCR json, Document Input, Human Output and Model Output details are empty.
To save the result of editing click UPDATE button.
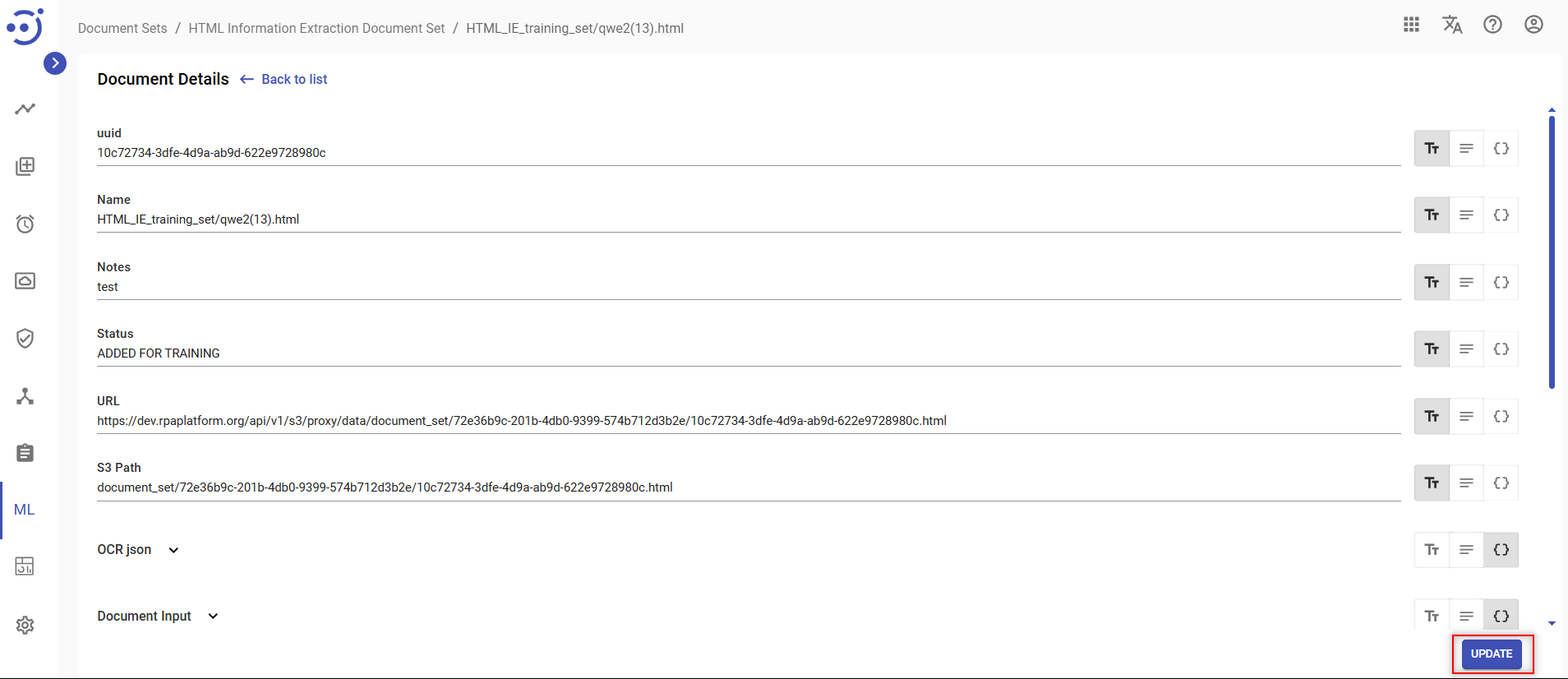
To edit document records, you need to be granted DocumentSet-UPDATE permission. See Role Permissions.
Delete Documents
There are 2 ways to Delete Documents from Document Set:
- Choose the Document or several Documents and press the icon Delete.
- To delete all documents from a document set, click Clear Document Set in the Actions menu and confirm deletion.
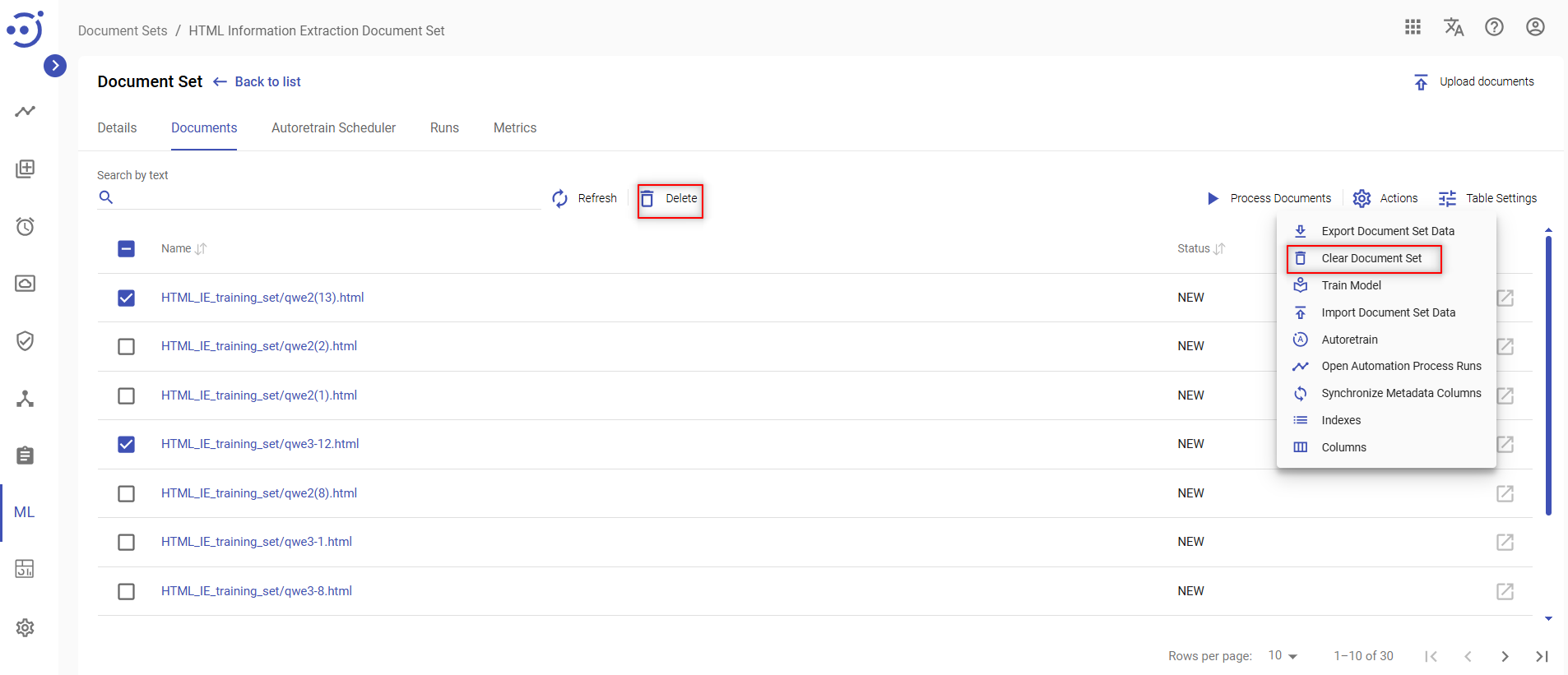
To delete documents, you need to be granted DocumentSet-UPDATE permission. See Role Permissions.
Process Documents
Process Documents dropdown menu encapsulates tools targeted at preparing quality data sets to train ML models.
If no documents are marked with checkmarks on the documents list, the actions will be performed on all documents in a document set. If there are documents marked with checkmarks on the documents list, the actions will be performed on the selected documents.
Selecting actions on the Process Documents dropdown menu will trigger Document Processor with specified actions. When a Document Processor starts working, its progress can be monitored in Runs Management and Automation Process Runs. Automation Process Runs can be accessed from Actions dropdown menu:
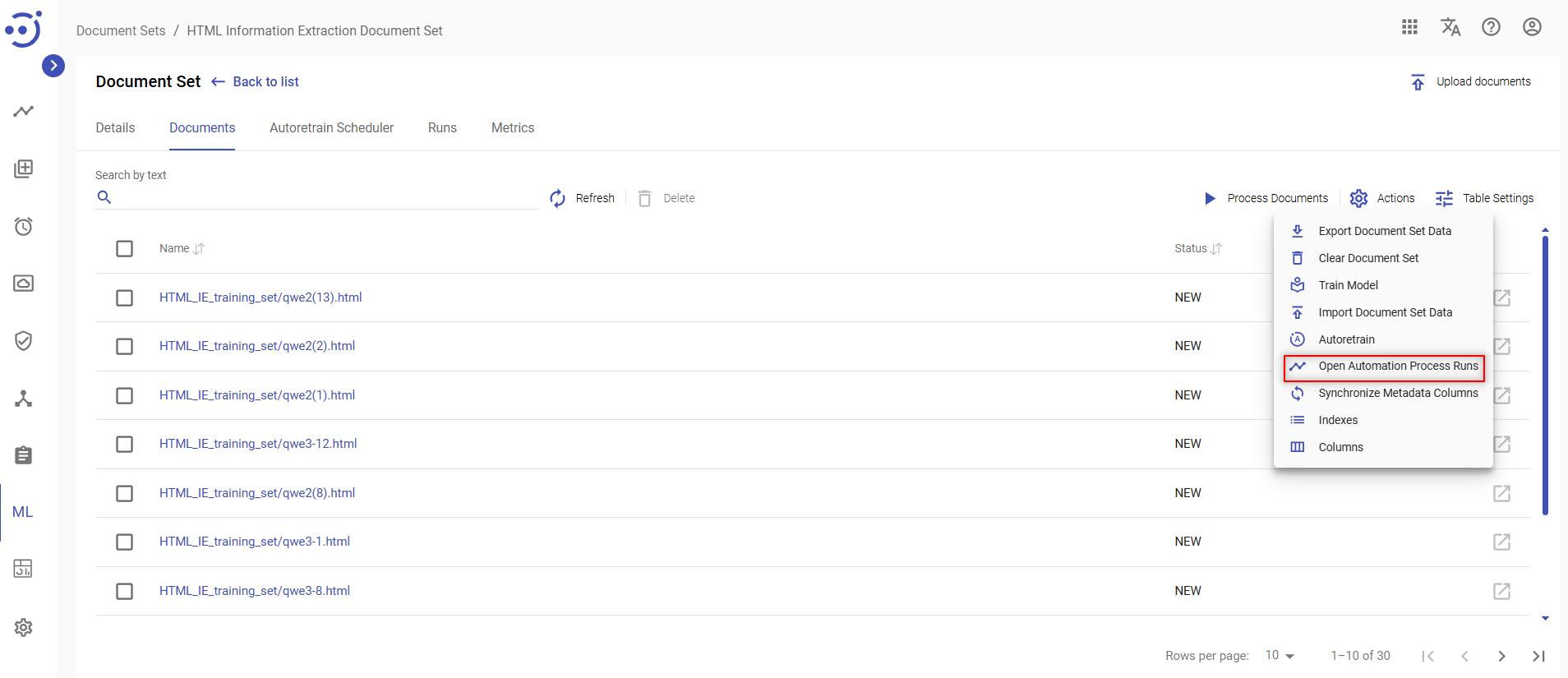
To process documents you need to be granted DocumentSet-ACTION permission. See Role Permissions.
Prepare Document Input for Tagging
To perform OCR conversion of documents and prepare document input for tagging, you need to:
- Click the Process Documents icon at the top of documents list.
- Place a checkmark next to Preprocess on the dropdown menu.
- Click the PROCESS button.
- Confirm your action.

As a result of the Preprocess action, OCR JSON and Document Input details are generated and can be viewed on the Document Details panel. This data contains the result of OCR in an appropriate format.
Execute Model
Document Input generated as a result of Preprocess action can be used for tagging a document by a ML model if such model already exists.
To launch document tagging by a ML model, you need to:
- Click the Process icon at the top of documents list.
- Place a checkmark next to Execute Model on the dropdown menu.
- Click the PROCESS button.
- Confirm your action.
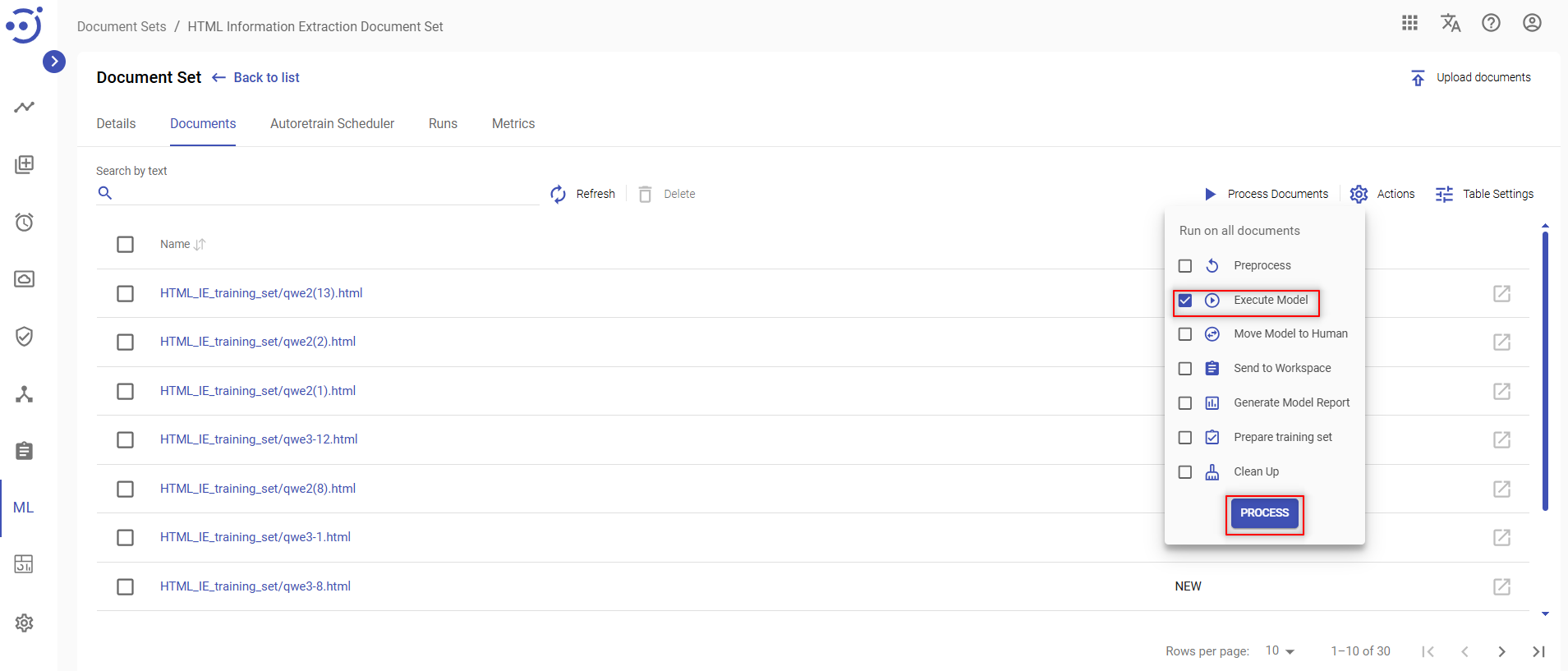
As a result of Execute Model action Model Output details are generated for a particular document and can be viewed on Document Details panel.
Move Model to Human
To review and edit tagging performed by a model after Execute Model action, you need to:
- Click the Process Documents icon at the top of the documents list.
- Place a checkmark next to Move Model to Human on the dropdown menu.
- Click the PROCESS button.
- Confirm your action.
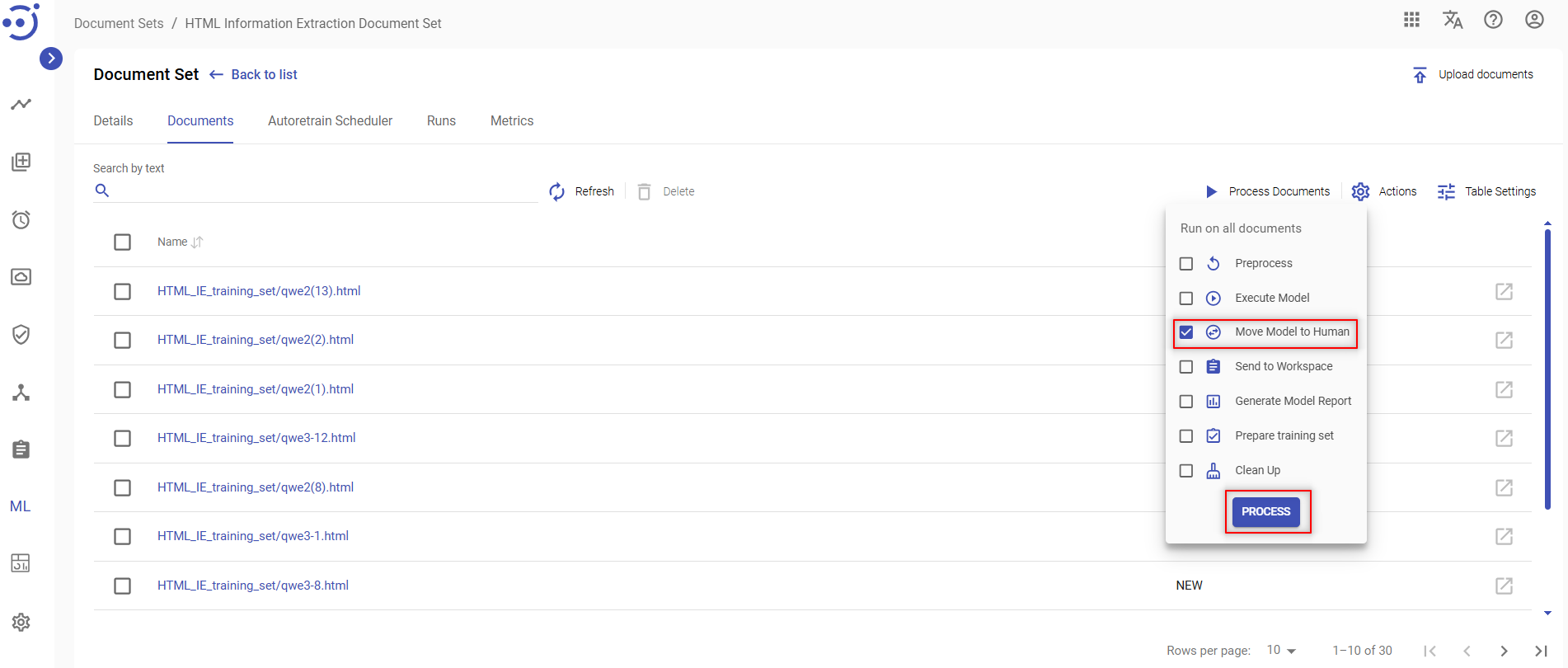
As a result of manual tagging, Human Output details are generated for a particular document and can be viewed on the Document Details panel.
Send to Workspace
Document Input generated as a result of a Preprocess action can be used for tagging a document in a Human Task.
To create a Human Task to perform documents tagging, you need to:
- Click the Process Documents icon at the top of the documents list.
- Place a checkmark next to Send to Workspace on the dropdown menu.
- Click the PROCESS button.
- Confirm your action.
Documents should appear in Workspace as a Human Task under corresponding Document Type and manual tagging can be performed.
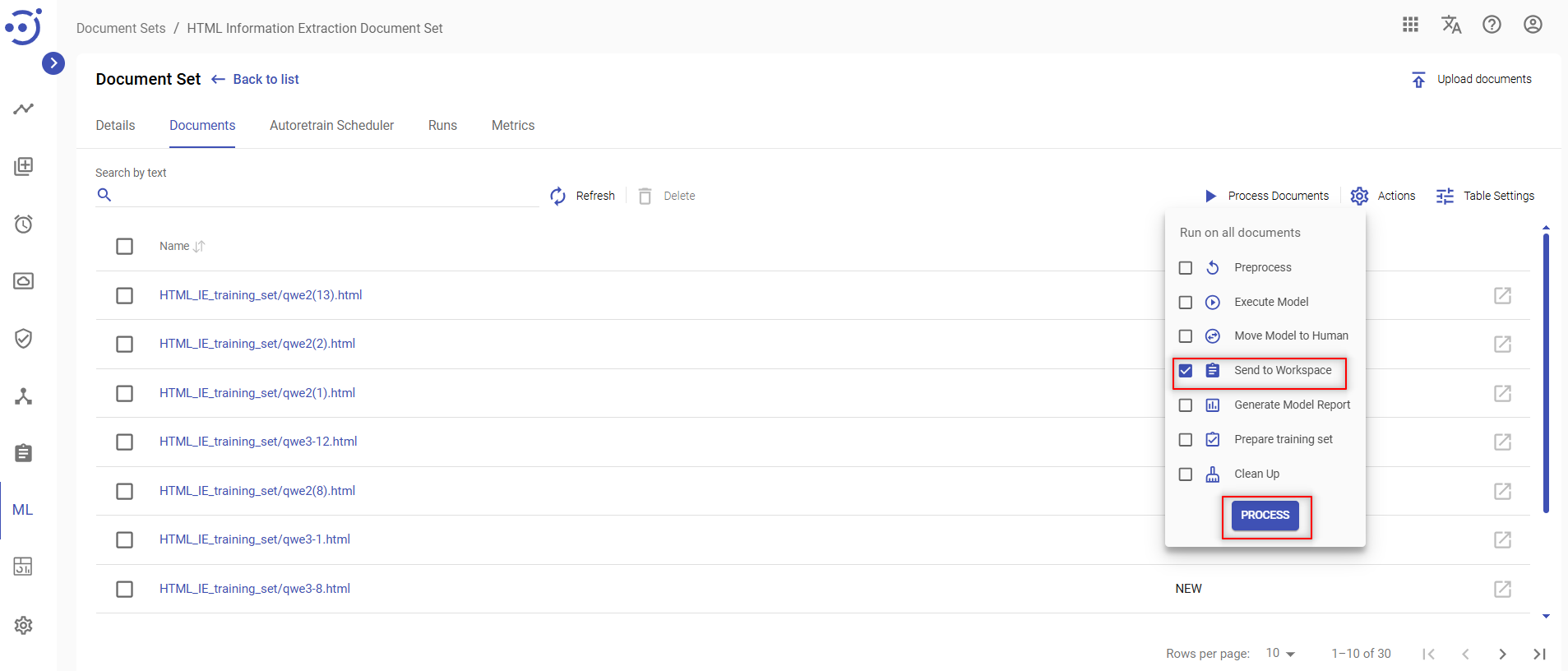
Another way to access a Human Task for tagging is to click Open Document icon (Ctrl + Open Document icon to open in a new tab) in the desired document row of the Documents tab.
After document is tagged, Human Output details are generated for a particular document and can be viewed on the Document Details panel.
Prepare training set
When tagging is completed the data needs to be prepared for model training.
To prepare data for model training, you need to:
- Click the Process Documents icon at the top of documents list.
- Place a checkmark next to Prepare training set on the dropdown menu.
- Click the PROCESS button.
- Confirm your action.
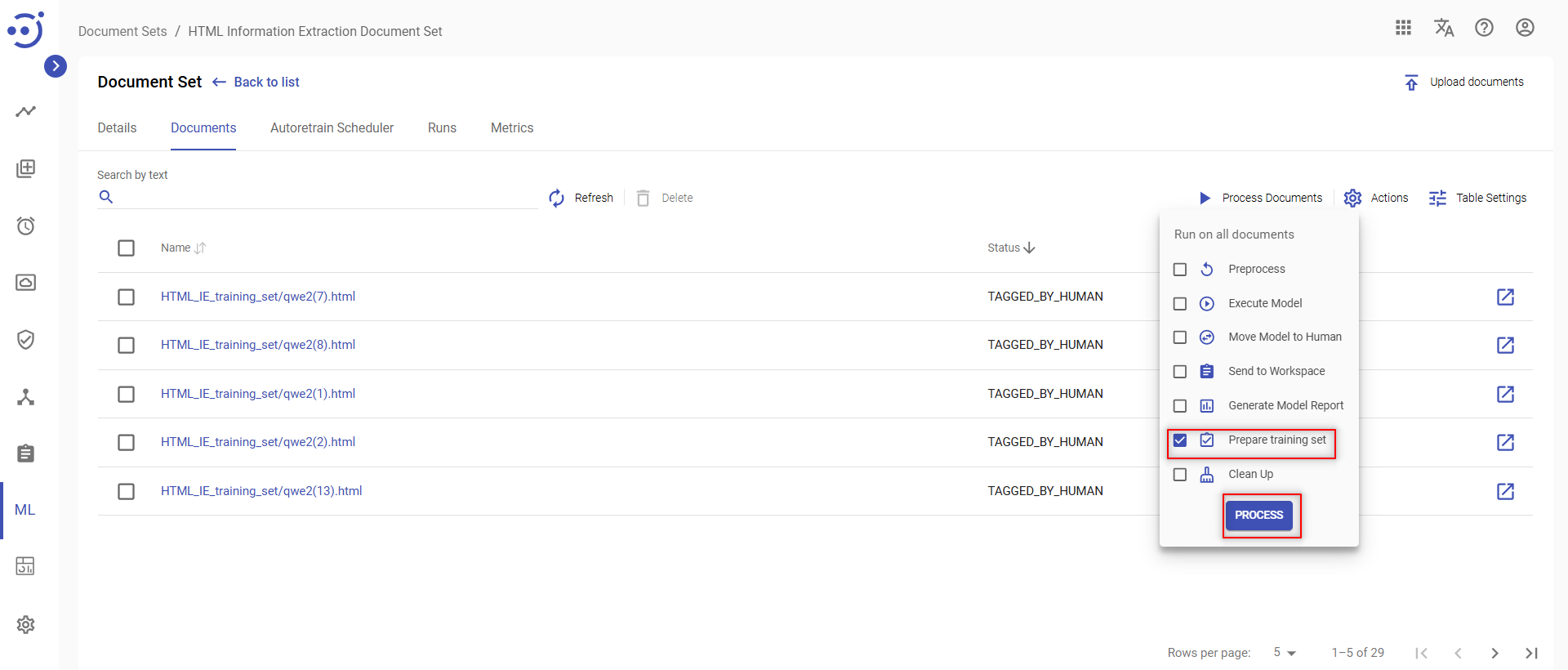
Now the training set is prepared and a ML model can be trained.
Generate Model Report
To calculate statistics and evaluate ML model performance, you should:
- Click the Process Documents icon at the top of documents list.
- Place a checkmark next to Generate Model Report on the dropdown menu.
- Click the PROCESS button.
- Confirm your action
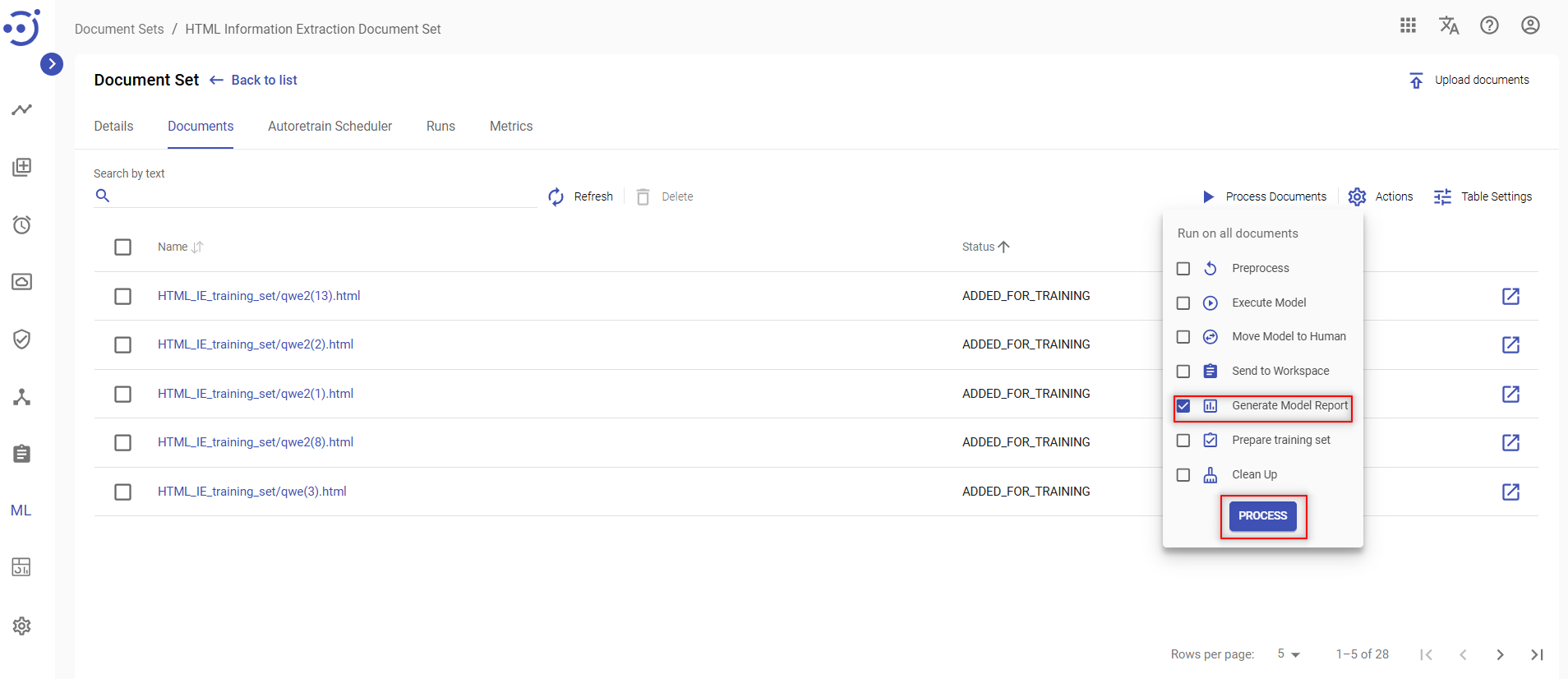
![]() Both model and human output results are required to generate model report.
Both model and human output results are required to generate model report.
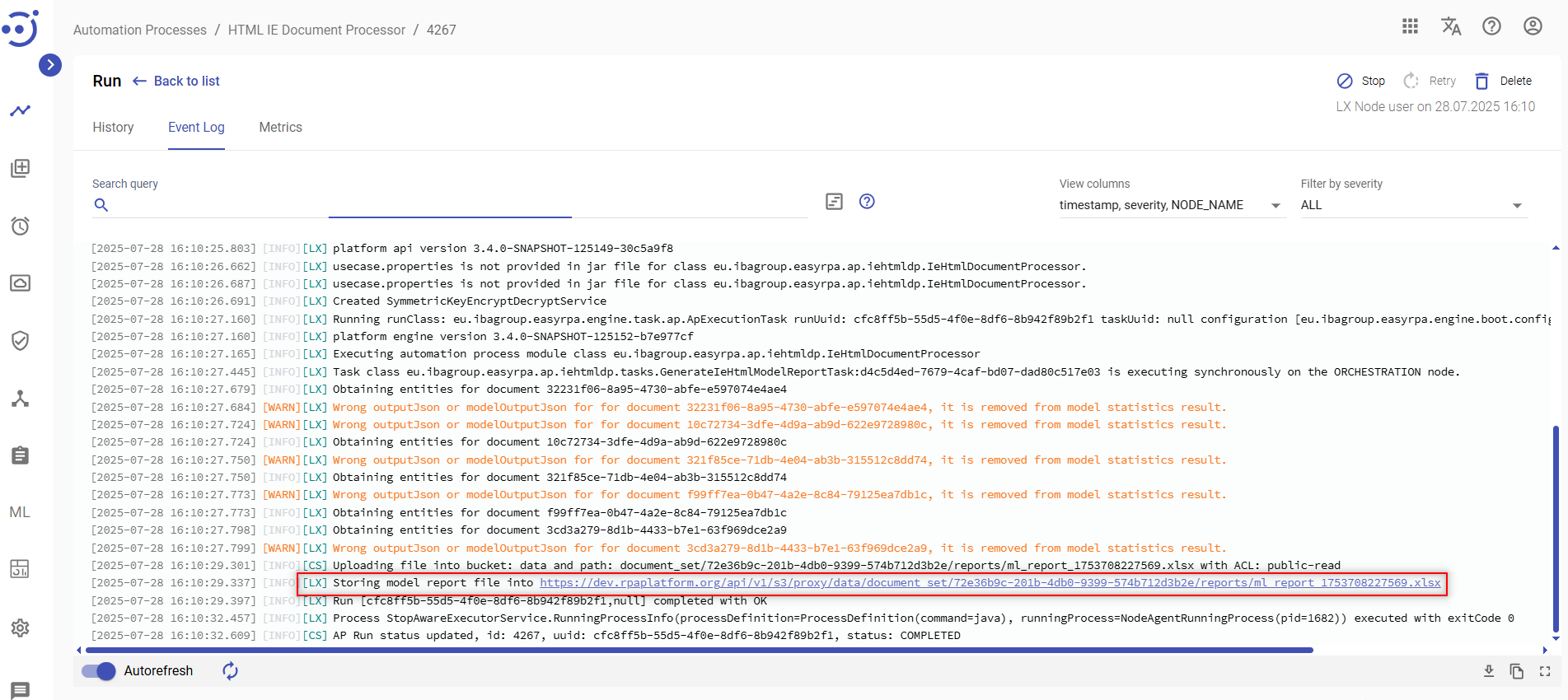
To download the model report, go to the Run Event Log, search for "Storing model report file" in search query, copy the URL and navigate to it. The report will be automatically downloaded to your computer.
Autoretrain
To start Autoretrain process you should:
- Click the Actions icon at the top of documents list.
- Select Autoretrain option on the dropdown menu.
The autoretraining process involves the following steps:
There are different tags assigned to documents depending on how they are tagged. Assigned tags can be viewed in the Autotraining JSON field. Please refer to the Tag rules for more information. In a document set, all documents are tagged regardless of whether they end up in a training or test set. Re_tag setting should be set to true if you want to overwrite labels on already tagged documents.
- According to the test_to_train_percentage coefficient specified in the document package settings, documents receive the TEST and TRAIN labels. It is also possible to view the TEST and TRAIN labels in the autotrain JSON field.
- Next, test and training sets are created: a document falls into either set if its tags match those set in the document package settings. In the Models module, you can find the new version of the training model determined in the Document Set details.
A new version of the model is trained on the training set. In the Models module, you can find the new version of the training model determined in the package details.
- A trained model is applied to a test set that has already been formed.
- Based on the results of the model run on the test set, a report is generated. In the Models module, you can find and download the report for the model version. A description of the values calculated in the report can be found in the Analysis of result section. In the Metrics module, you can also find information about the metrics of model versions trained on this Document Set.
A model will be marked as the best version in Models module according to the switch_best_model setting. Based on accuracy and recall metrics, the best model is selected. Additionally, the assessment_rule and average_group_keys_assessment settings can be configured to determine the calculation criteria. It is also possible to manually select the best model version.
Document Set is cleaned up according to the cleanup settings.
All steps described above does not apply to the document if the INVALID Document checkbox is checked for the Document on the More tab.
For more information on Autoretrainig setting please refer to Autoretrain settings.
Export Document Set Data
A document set can be exported as a .zip package containing a complete set of historical data about the document set including metadata JSON file, initial document set files as well as files created as the result of document processor workflow conversions, a .csv containing all records.
To export a document set click Export Document Set Data icon on the Actions menu.
To export a document set, you need to be granted DocumentSet-READ permission. See Role Permissions.
You can also export a document set using Export Document Set Data icon on Document Sets page. See Document Sets.
Import Document Set Data
A .zip package with a document set that was earlier exported via Export Document Set Data and containing a complete set of files and records can be imported. All files from an imported .zip are saved to File Storage overriding existing files, new records are added to a document set datastore, all File Storage references are replaced with new paths.
To import a document set click Import Document Set Data icon on the Actions menu.
To import a document set, you need to be granted DocumentSet-UPDATE permission. See Role Permissions.
Train Model
To train a model on a prepared training set, you need to:
- click Train Model icon on the Actions menu.
- In the appeared dialog box you need to provide the following details:
- Trainer - a name of the model trainer
- Name - a name of the model to be trained.
- Description – a short description.
- Version – a model version.
- Training configurations JSON – JSON which defines configuration parameters for the training process. Can be changed or leave unchanged.
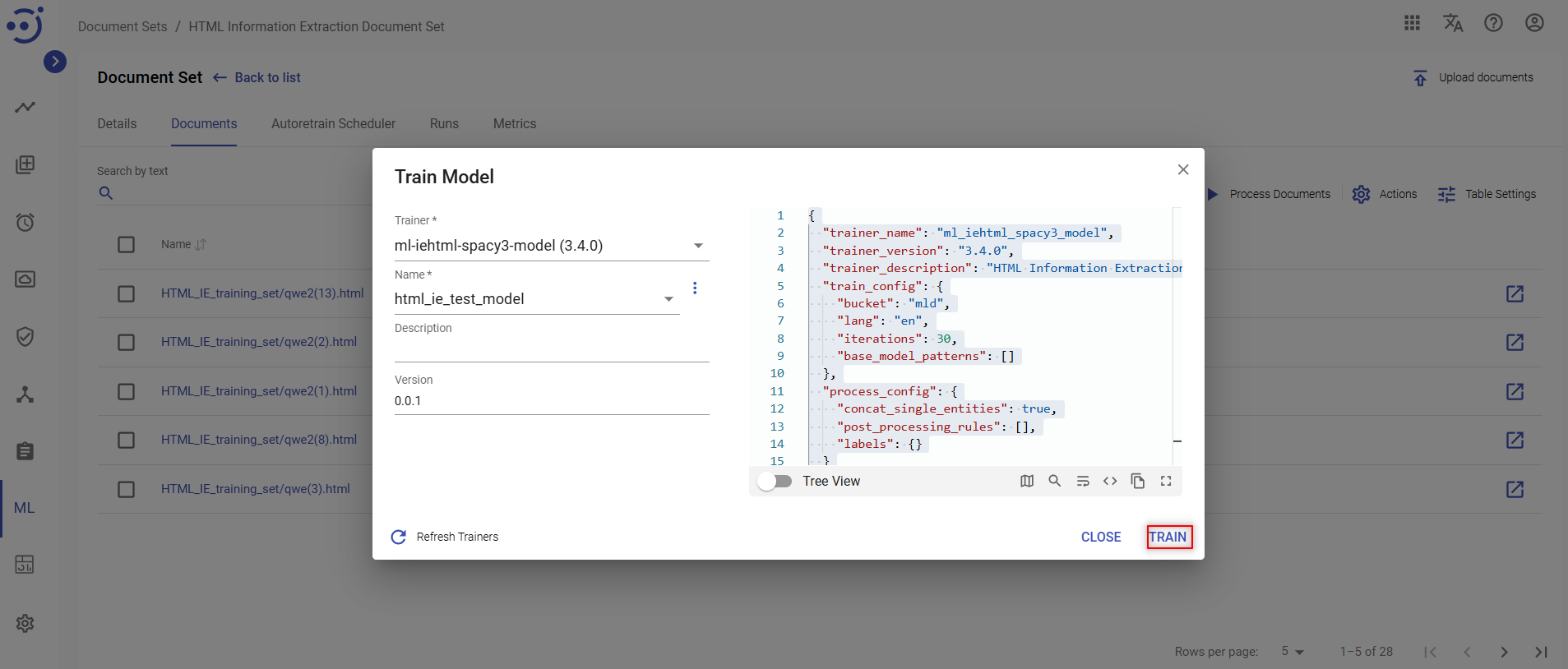
- Click TRAIN to start ML model training.
To train a model , you need to be granted MlModel-CREATE permission. See Role Permissions.
Model Training can also be launched from the Document Sets page. See Document Sets.
Synchronize Metadata Columns
To add columns from the Metadata section and populates the fields based on the data entered by the user in the document's More tab, you need to:
- click Synchronize Metadata Columns icon on the Actions menu.
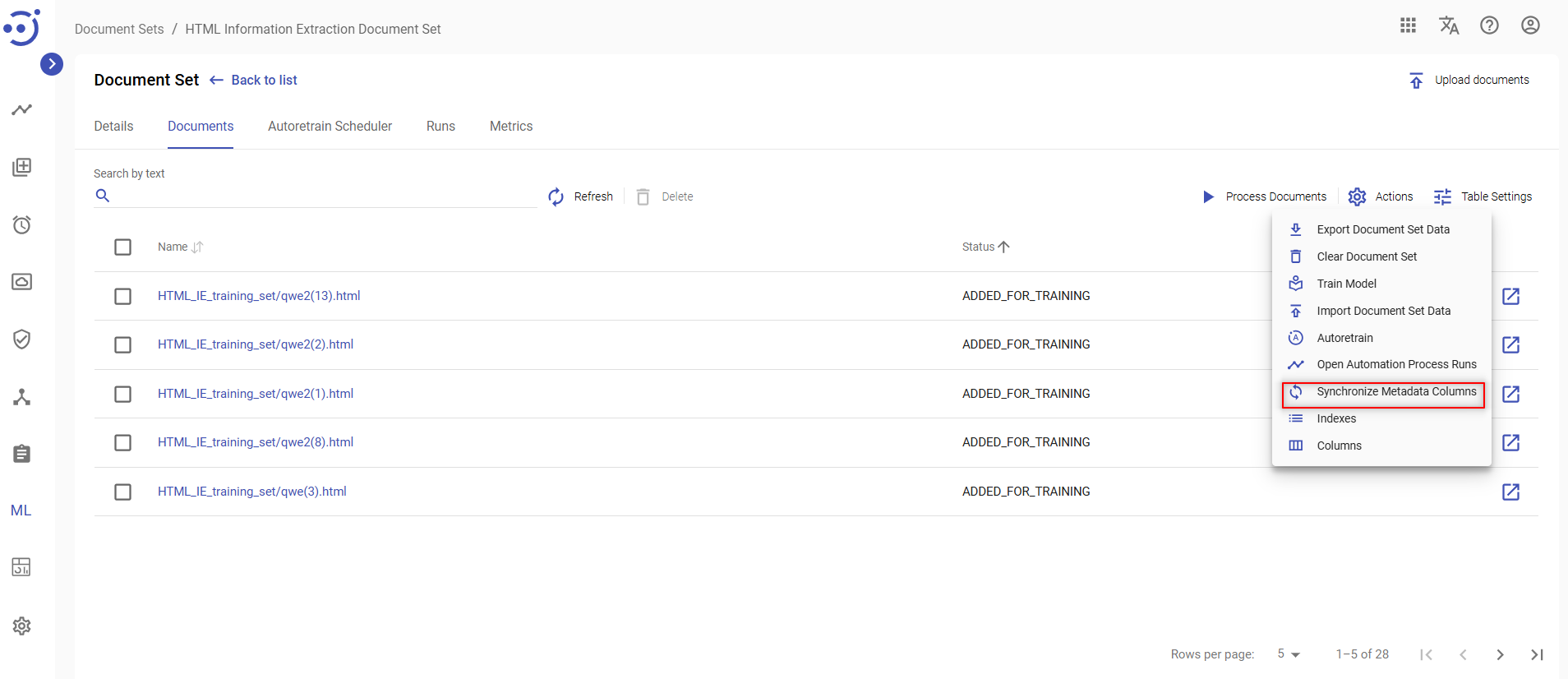
- In the appeared dialog box you need to confirm your action.
As a result all columns from the Metadata section with the user-entered data added in table.
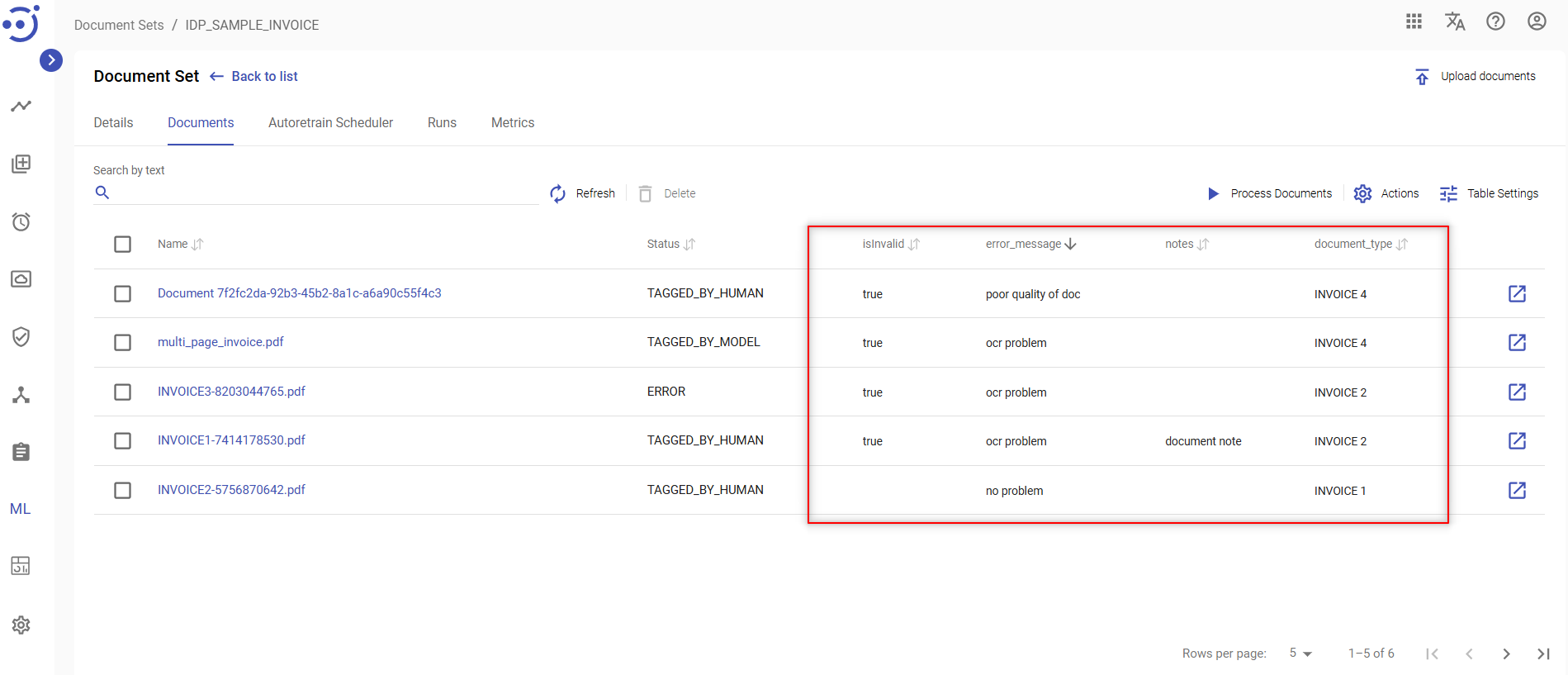
Synchronize the metadata columns before the user fills in the corresponding data in the document. Otherwise, you must resave the document to add data to the metadata columns.
Documents Status Lifecycle
The lifecycle of a document is designed as a series of linked statuses that starts with creation of a document and follow it through multiple processing steps. Status changes occur as a document goes through its lifecycle.
When the document is sent to a workflow, it passes the following statuses:
- NEW - a document is created;
- OCR_PROCESSING - a document is being digitized with OCR;
- READY_FOR_TAGGING - a document is converted to be ready for displaying and processing in a Human Task and Machine Learning;
- TAGGING_BY_HUMAN - a document is being processed in a Human Task;
- TAGGING_BY_MODEL - a document is being processed by a Machine Learning model;
- TAGGED_BY_HUMAN - processing of a document in a Human Task is completed;
- TAGGED_BY_MODEL - processing of a document by Machine Learning model is completed.
- ADDED_FOR_TRAINING - a document set is prepared for model training.