Details
Details
The Documents page contains key information about an existing document set, its processing lifecycle and configuration parameters. You can view/edit document set details, OCR configuration parameters, and manage documents. To view the document set details, you need to be granted DocumentSet-READ permission. See Role Permissions.
To access Documents, you need to:
- Navigate to the Document Sets page.
- Click on the corresponding Document Set Name.

Details
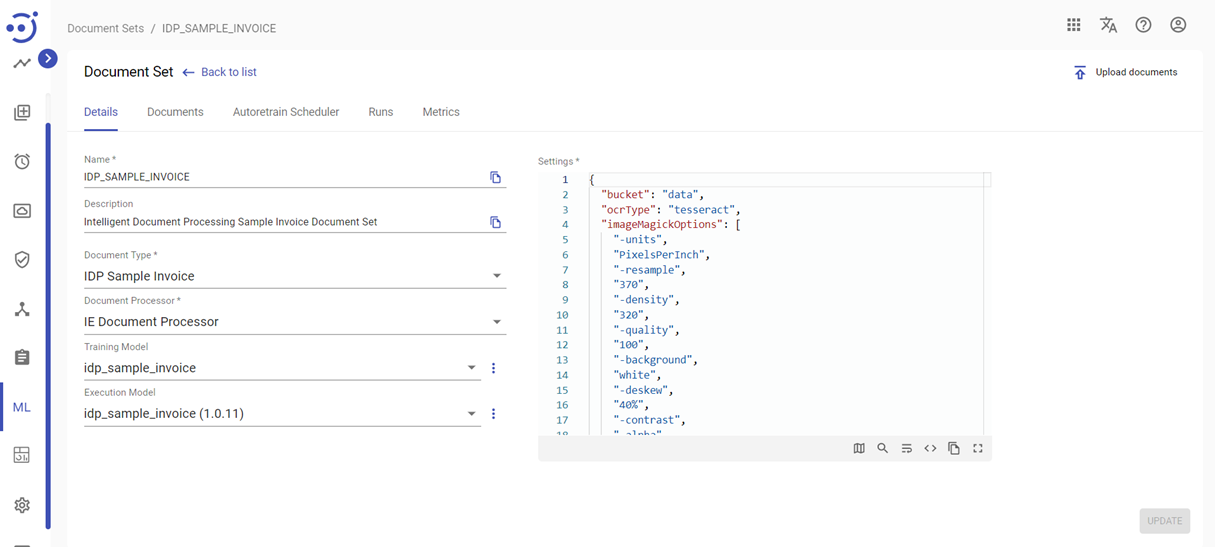
The Details tab displays general settings that are necessary for the document set creation and processing.
You can view/edit the following information about a document set on the Details tab:
- Name – the document set name;
- Description – the document set short description;
- Document Type – a human task document type to be selected from the dropdown list;
- Document Processor – an automation process for the document set workflow. The document processor includes converting PDFs into images format, image improvements using ImageMagick scripts, sending images to OCR, sending documents with OCR response to Human Task, processing Human Task response to convert results into Machine Learning input format.
- Training Model – a ML base model used to train the ML model version.
- Execution Model – a ML model used to process the document set.
- Settings - OCR configuration including Storage bucket name, Tesseract options and Image Magick options:
- document_bucket – name of Storage bucket where OCR results will be saved.
- tesseractOptions - Tesseract OCR command line options. Please see the external documentation Tesseract Command Line Usage.
- imageMagickOptions - ImageMagick command line options. ImageMagick tool is used to split pdf by pages and print as images. Please follow Image Magick Command Line Documentation.
- imagePostprocessScripts - optional image post-processing scripts. If specified will be run against image magic split results. Optional imagePostprocessScriptsBucket parameter allows providing scripts from and AP managed S3 bucket. If not provided - the default is 'rpaplatform/scripts'
- autotraining - settings for model autotraining.
- To save the result of editing click UPDATE.
To manage documents within an existing document set click the Documents tab.