Step 2. Collect and prepare training set (IE)
Step 2. Collect and prepare training set (IE)
To prepare the Training Set which is used to train a new ML model, you need to create a new Document Set entity. Click Machine Learning - Document Sets - Create New:
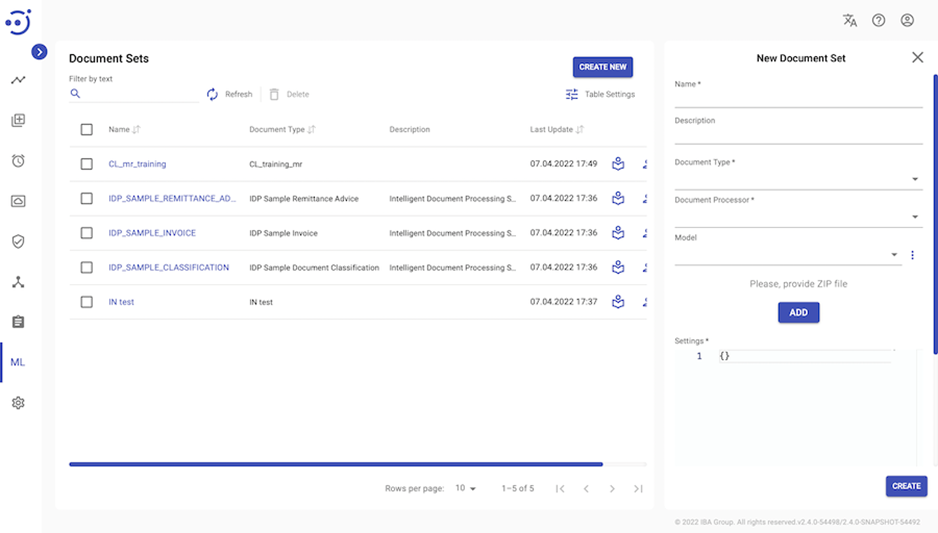
Training set preparation contains the following steps:
Provide ZIP file
Documents are the main part of your training set. ZIP archive must contain the documents that will be used to train a new machine learning model.
The archive should look like this:
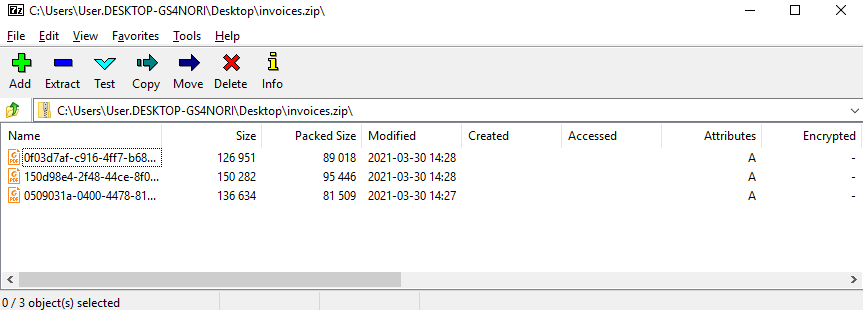
You can find and download document set for testing by the following link: Intelligent Document Processing (IDP).
Select Document Type
Select Document Type created in the previous step. Document Type describes how your documents should be displayed on the Human Task for tagging and what fields should be extracted during tagging and Machine Learning training.
Select Document Processor
Document Processor is a special process which includes preparation steps to display your documents on the Human Task.
To process HTML or TXT input documents "IE HTML Document Processor" should be selected. To process PDFs and Images for Information Extraction, EasyRPA provides "IE Document Processor" which should be selected in our case. For more information, please follow the link: Document Processor. This processor includes:
- converting PDFs into images format
- images improvements using ImageMagick scripts
- sending images to OCR
- sending documents with OCR response to Human Task
- process Human Task response to convert results into Machine Learning input format
You can create a Document Set after providing the ZIP archive, selecting the Document Type and Document Processor. Documents from your Document Set will be uploaded to File Storage. The details of each document in a Document Set can be found by opening it:
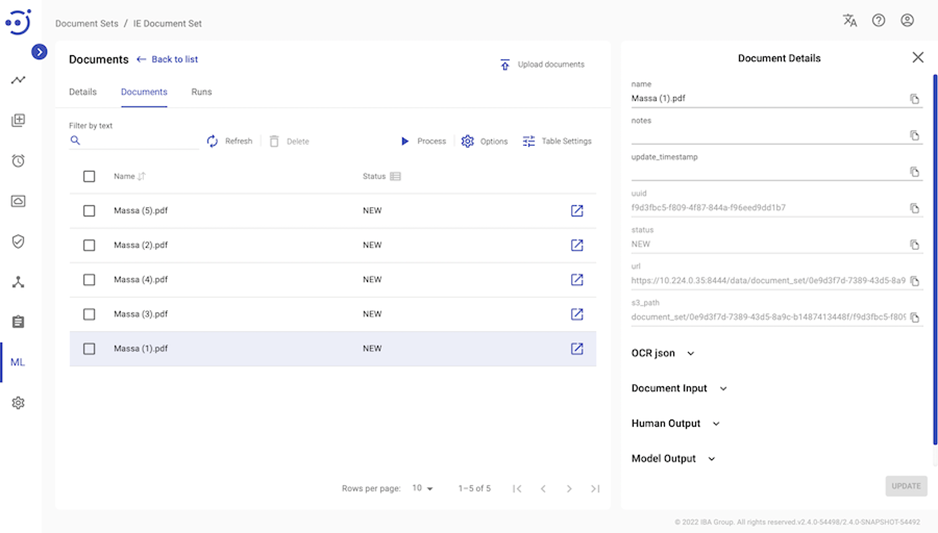
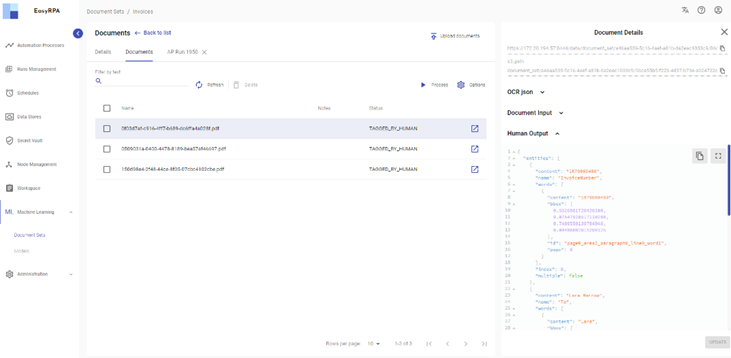
As this Document Set is new, Document Input, Human Output and Model Output details are empty.
Generate Document Input
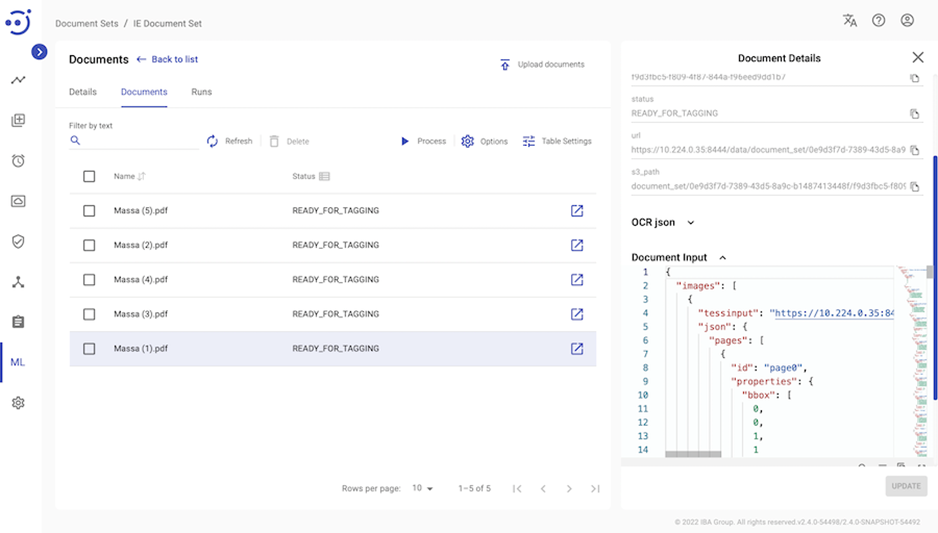
Document Input is data that comes as an input to Human Tasks. Document Processors are responsible for preparing that input. For Document Processor to be triggered and for Document Input to be prepared, you must select "Preprocess" from the action menu and then confirm the dialog that appears:
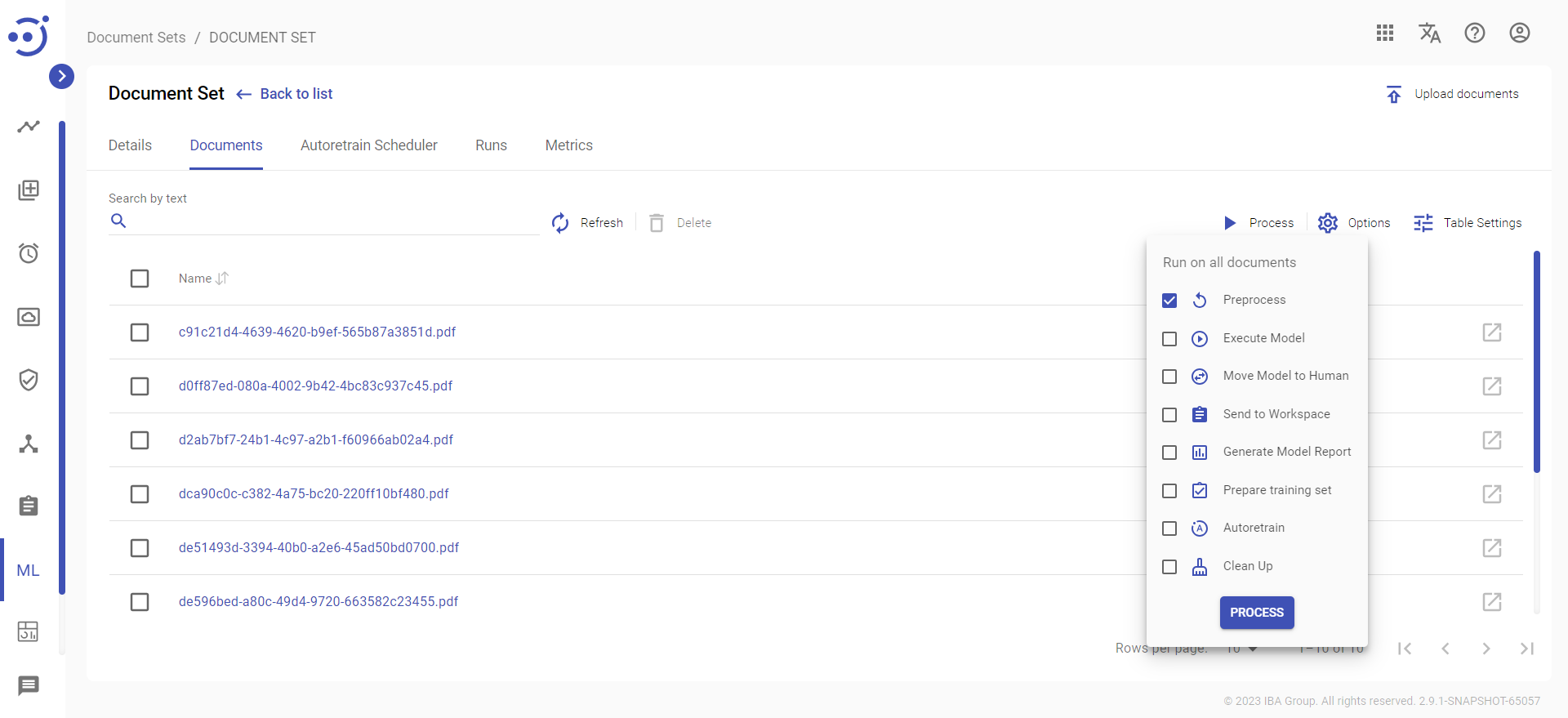
Document Processor will start working. You can monitor its progress in the Runs Management section. Wait until all documents have the status "READY_FOR_TAGGING". As a result, "Document input" details will be generated in which you can see the input data from Human Task. In these details, the result of OCR in an appropriate format can be seen:
Move documents to Human Task and tag them
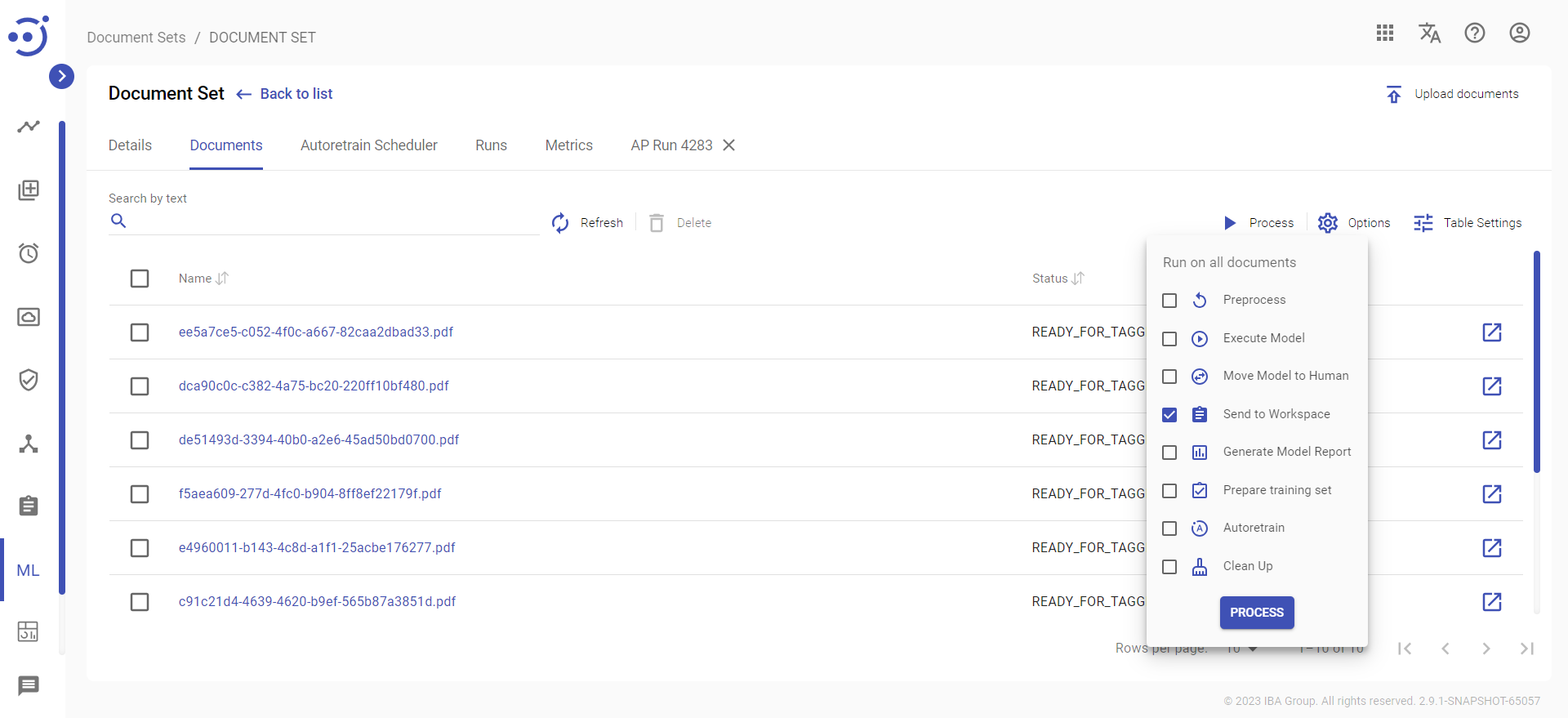
The next step is to tag the documents. This result of tagging will be used by ML algorithms to train a model. For your Document Set to move to Workspace and to let workers tag them via a Human Task, you must select the "Send to Workspace" action:
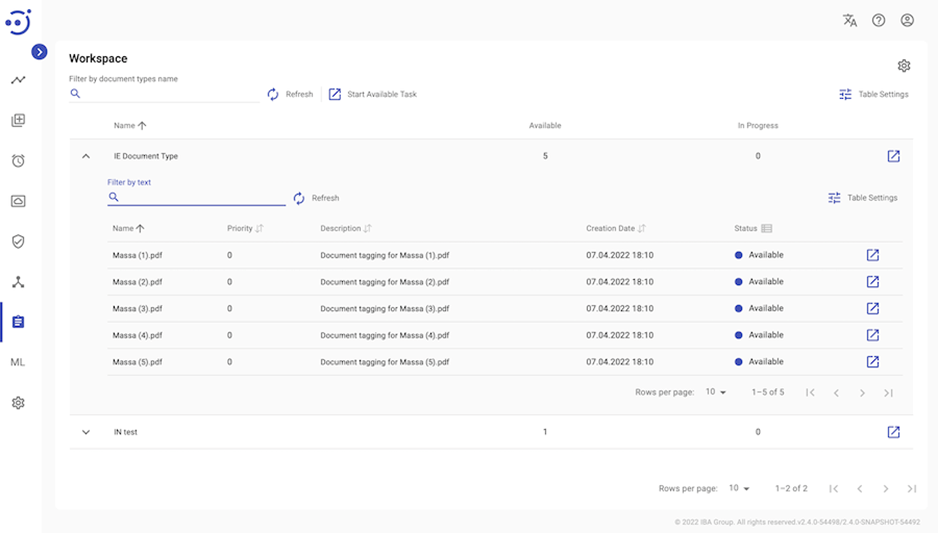
Documents should appear in Workspace under corresponding Document Types. To tag them, click the button "Start Working":
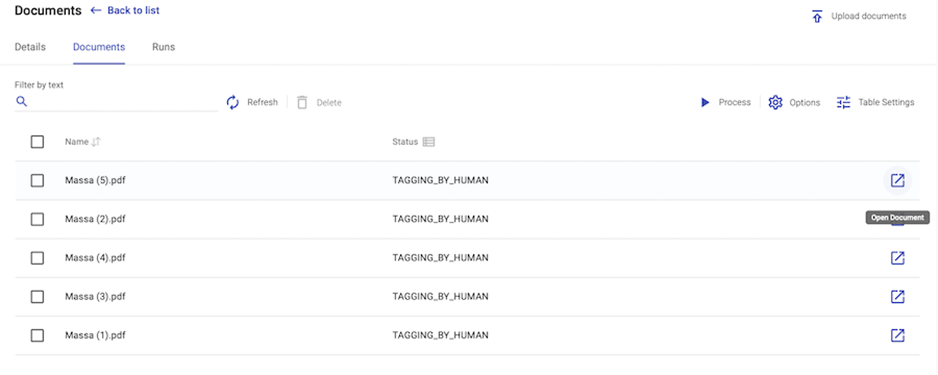
A document can also be tagged without being sent to the Workspace. Click "Open Document" next to the status label in the Document Set details:
You can start tagging documents:
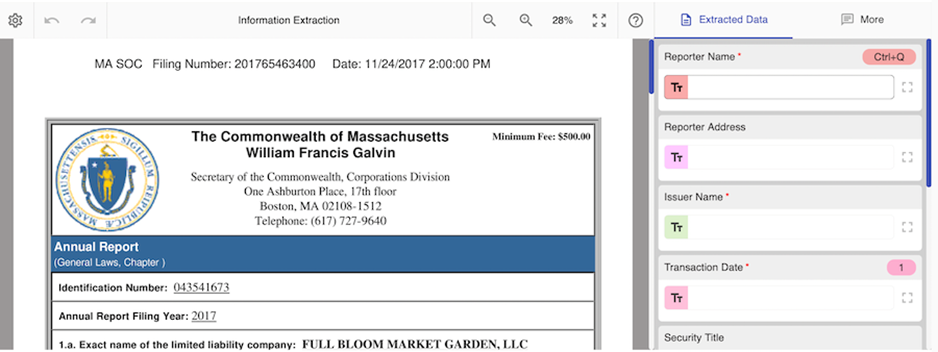
After a document is tagged, "Human Output" details are generated for that particular document:
For more information about tagging process, please refer to the following links: Sample Information Extraction Task and HTML Information Extraction Task and Tagging Overview.
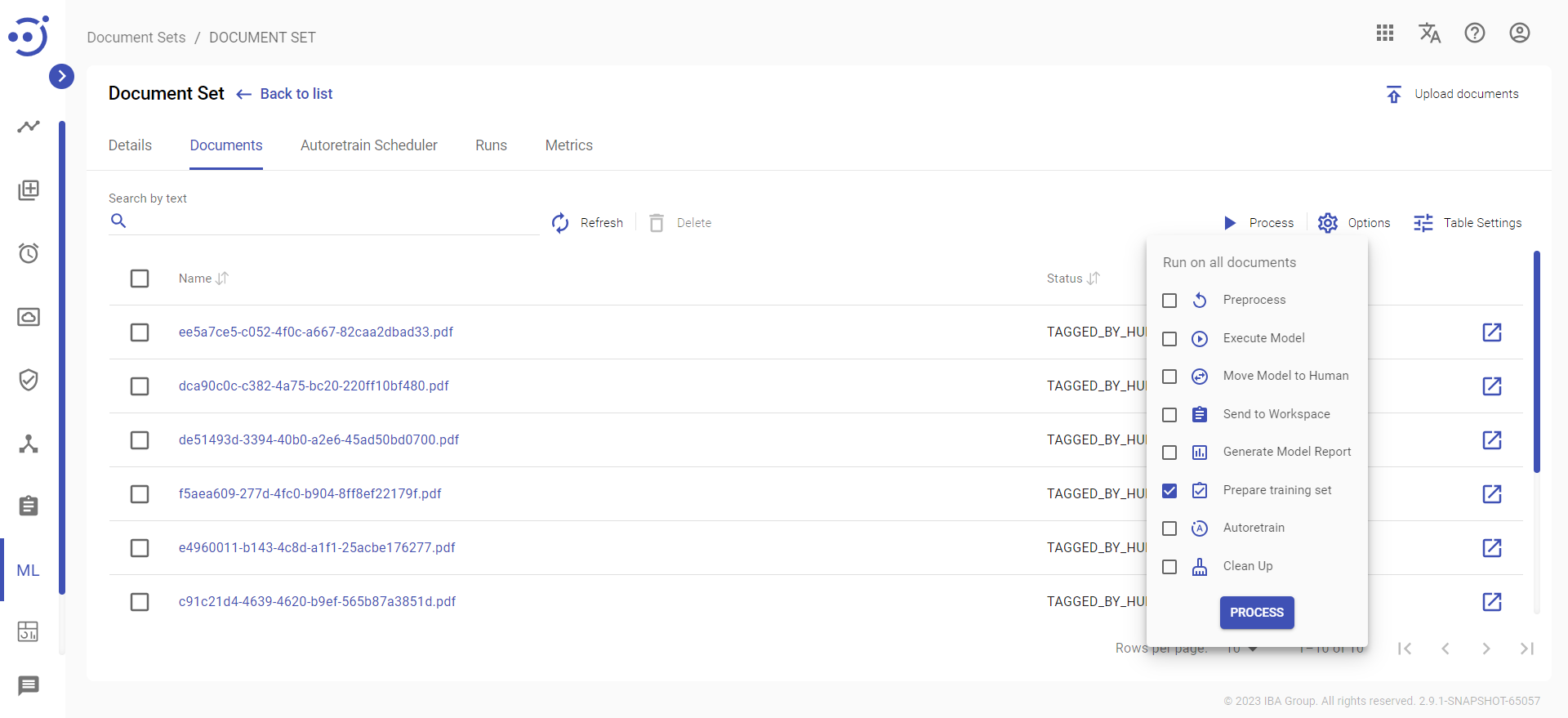
To finish Training set preparation click Process - Prepare training set and confirm your action with the Process button:
Once you have completed these actions, you can start training your model.