Information Extraction Models
Information Extraction Models
Overview
Information extraction (IE) is the automated retrieval of specific information related to a selected topic from input data. Information extraction tools make it possible to pull information from text documents, databases, websites or multiple sources.
EasyRPA provides infrastructure to create and run machine learning models that extract information from PDF, images, TXT and HTML documents.
Curentlly platform has the following IE set of models:
- hOCR source base
- HTML source base
hOCR source
The input document are PDF and images that are converted into hOCR using platforms OCR.
Where image[] - are the pages of a source document, and for every page are:
- text_src - text from OCR
- hocr_src - the OCR result in hOCR format
- json_src - the hOCR file reperesented as JSON for IE Human Task Type
- content - the source page image
A list of entities is the result of the model execution. An entity consists of a label name, count index, label content, and OCR words that match the entity region.
HTML source
The input document is HTML (TXT, DOCX files. if provided as input, are converted into HTML automatically)
Tagged HTML is the result of model execution. Tagged HTML consist of rpa-selection tags with information about label and order (multiple case)
Spacy IE Models
Platform uses spacy NLP inside for data processing for the following models:
- ml_ie_spacy2_model
- ml_ie_spacy3_model
- ml_iehtml_spacy2_model
- ml_iehtml_spacy3_model
Information Extraction as a Pipeline
Information Extraction process is implemented in EasyRPA as a pipeline. There is more to this pipeline than ML models: platform also includes several options for extending ML with rules and dictionaries.
Taking a closer look at both processes, let's investigate what stages are part of each: model training and execution.
Model Training Process

Model training
This step of EasyRPA involves training the ML model using the provided training set. The system automatically shuffles the provided set, runs training for a specified number of iterations, and selects the best model.
Process developer can specify a model type, number of training iterations, etc. using a configuration JSON file.
Package creation
The trained model comes packaged with configuration files and uploaded to the Nexus repo.
Information Extraction Process

Model execution
The model is run once for each document.
Model Training Configuration File
To train a Spacy Information Extraction models you need to provide a JSON that defines configuration parameters for the training process.
Let's take a closer look at these configuration settings.
- trainer_name(string)(required) - a python artifact that produces model packages for processing with a specific model type. There are two modules in it: a module for training on tagged data and generating a trained model package, and a module for downloading the trained model from the Nexus or from the cache and running it on the input data. Please, refer to Out of the box IE models and Out of the box IEHTML models for more details.
- trainer_version(string)(required) - a trainer version. Please, refer to Out of the box IE models and Out of the box IEHTML models for more details.
- trainer_description(string)(required) - a trainer description.
- lang(string)(optional) - the language of input data. The default value is 'en'.
- iterations(number)(optional) - number of iterations of model training on a given training set. The default value is '30'.
- concat_single_entities(boolean)(optional) - Spacy know nothing about sinle/multiple entity, for it they are always multiple. This flag uses labels configuration (from train_config.json) to concatinates spacy entities with the same name into one string.
- post_processing_rules(list of objects)(optional) - after NER extraction model uses EntityMatcher with rules defined in post_processing_rules.json. Configuration JSON should contain a list of label names with regular expressions for searching for entities.
- base_model_patterns(list of objects)(optional) - used to configure EntityRuler for labeling datum elements. It runs before fetching data and provides model with additional information on the document structure increasing accuracy of data extraction.
Model Training Data File
To train a Spacy Information Extraction models system provides train_data.json.
Where:
- data - the list of documents with tagged entities, provided by Information Extraction HTT
- labels(list of objects)(optional) - labels are added to the NER pipe at the training stage. In case of empty configuration all labels found in the training dataset will be automatically added to the model, and the output dimension will be inferred automatically (expensive operation). The multiplicity flag affects how the entity index is calculated at processing stage. Index of labels with multiplicity equals True increments through the whole document while for labels with False multiplicity index is always zero.
OpenAI IE Models
The OpenAI model uses OpenAI API to call LLM for request processing. The idea of such models are minifies (depending of specified renderer in model configuration) input document (HTML or HOCR), then send request to OpenAI that extract fields (or something else) and provide the result in CSV format.
Curentlly platform has the following OpenAI IE models:
- ml_ie_openai_model - uses hOCR source base
- ml_iehtml_openai_model - uses HTML source base
The models do not need a training, so do not require training data, but support a train operation. The result of the training will be a trained model with a default prompts specified during training. It is kind of prompts versioning.
ml_ie_openai_model
This model minifies (depending of hocr2html rendering selected in model configuration) hOCR html, then send to OpenAI request like this:
You are a good expert of extracting data from invoice documents. You receive HTML document as the result of OCR processing of scanned invoice, and the list of fields you should extract.
As an output you have to provide csv file with two columns: field tag and list of HTML tags "id" property. Pay attention that one extracted field may have several tags.
For table items provide a separate line for each row.
For example:
###BEGIN OF EXAMPLE
User ask you to extract:
```
Find all accounts in the balance sheet and for each item found extract:
- company name with tag COMPANY
- account with tag ACCOUNT
- balance with tag BALANCE
Do not tag table headers.
```
Your input HTML is:
```html
<html>
<body>
<p>
<div><span id="word_0_1">Remittance</span><span id="word_0_2">Advice</span></div>
<div><span id="word_0_3">Company:</span> <span id="word_0_4">IBA</span><span id="word_0_5">Group</span></div>
<div><span id="word_0_6">Income</span><span id="word_0_7">Fund</span></div>
</p>
<p>
<div><span id="word_1_1">ACCOUNTS</span><span id="word_1_2">BALANCE</span></div>
<div><span id="word_1_3">12341234</span><span id="word_1_4">$5000</span></div>
<div><span id="word_1_5">22354123</span><span id="word_1_6">$1000</span></div>
</p>
</body>
</html>
```
Your answer always should be a only valid csv file without any comment, do not ommit headers, always use " for values escaping:
```csv
"field_name","tag_id"
"COMPANY","word_0_4,word_0_5"
"ACCOUNT","word_1_3"
"BALANCE","word_1_4"
"ACCOUNT","word_1_5"
"BALANCE","word_1_6"
```
Note, that you
###END OF EXAMPLE
Now your task is the following:
```
Find all items in the invoice and for each item found extract:
- item name with tag PRODUCT. If there is no item in the invoice, split the description into item and description: where item it is the first sentence in the description
- description with tag DESCRIPTION
- unit price with tag PRICE.
- quantity with tag QUANTITY
Do not tag table headers. Combine multiple lines of description tag into one tag if possible.
Also extract invoice information:
- Company name of the client with tag CLIENT
- Client address with tag ADDRESS
- Invoice number with tag INVOICENUMBER
- Date of issue with tag ISSUED
- Due Date with tag DUE_DATE
- Total amount, TOTAL
```
Your input HTML is:
```html
{html}
```The OpenAI request is customizable, how to do this we explains below.
Model Training
Training proces creates a new model with default promtps configuration. The trainer do not use the training data, the only training configuration will be used. Here is sample model training configuration.
where:
- prompts_config - the default prompts configuration saved into trained model
- messages - a prompt messages structure to use during sending to OpenAI API
- html - the document simplified html that model creates and injected into prompt context
- environment - a secret vault aliace where stored JSON with environment variables to set, before call the LLM API
temperature - the request temperature, depends of LLM model, ussually can be gradated like: Coding / Math - 0.0; Data Cleaning / Data Analysis 1.0; Creative Writing / Poetry - 1.5
- open_ai_model - an OpenAI model to use, required
- track_into_langfuse - track the OpenAI conversation into Langfuse if true
- use_batch_api - use OpenAI batch API to perform chat promt request, it is asynchronius and has tess token price, but could has not been implemented for specific LLM provider
- batch_api_completion_window - the batch API completion window
- entities - an entity to response tag mapping to map OpenAI tagged document into documents entities. The single flag is using to process concat_single_entities.
- debug - boolean switches debug messages on
- concat_single_entities (boolean)(optional) - This flag uses entities configuration to concatinates entities with the same name into one string.
- hocr2html - HOCR to html rendering configuration
OpenAI models environment
To use OpenAI API you need to specify LLM provider url and access token in environment variables (OPENAI_BASE_URL, OPENAI_API_KEY).
The model configuration defines the environment variable that is aliace of Secret Vault record that contains environment variable JSON to set befor use OpenAI API.
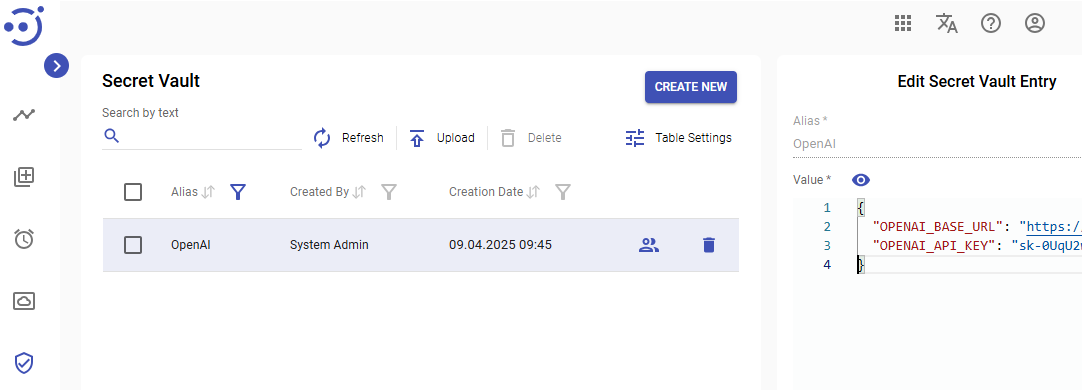
Here is the JSON template for it:
{
"OPENAI_BASE_URL": "https://a_llm_host.org",
"OPENAI_API_KEY": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}Prompts configuration
The prompts_config is a map of parameter the model use to create a OpenAI request. Model get it from:
- configuration parameter of the MlTask call
- model default configuration
The MlTask configuration parameter overrides the existing model default configuration, i.e. you can add only a changes iteration into MlTask and keep the existing from default.
Here is a platform task code that prepare Ml call:
MlTaskData mlTaskData = new MlTaskData(modelName, modelVersion);
mlTaskData.getConfiguration().putAll(documentContext.getMlConfiguration());
. . . . .
default Map getMlConfiguration() {
return (Map) getSettings().getOrDefault("mlConfiguration", new HashMap());
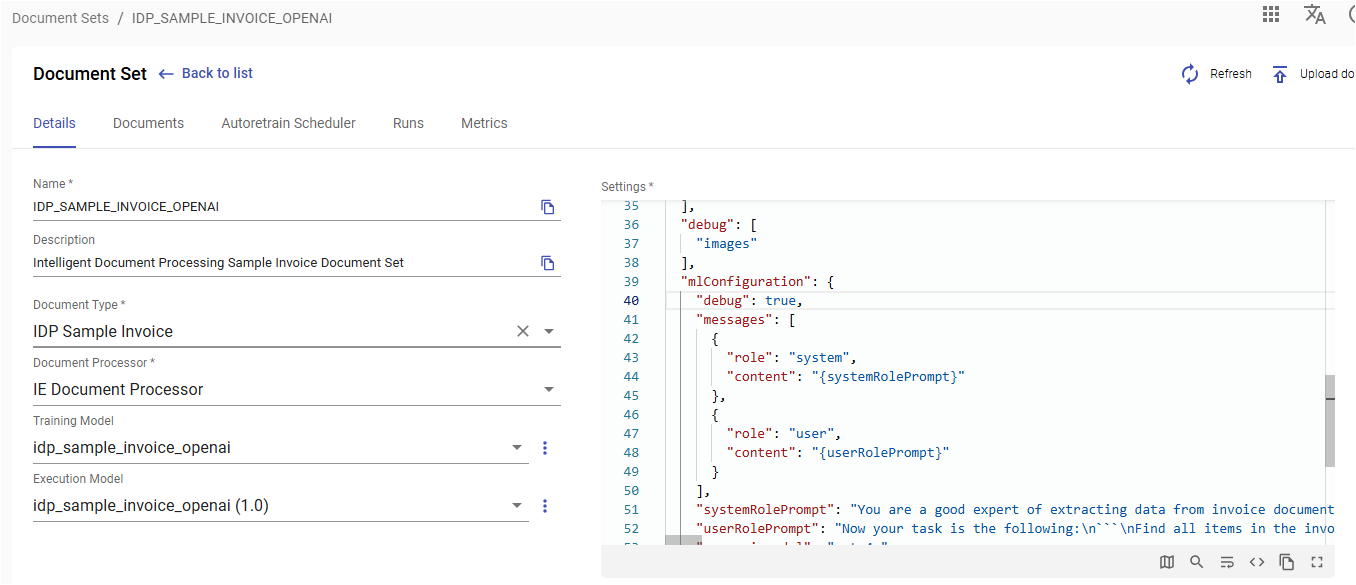
}So to pass the promts into the model, you need to specify mlConfiguration map in document set settings of document processor configuraion:
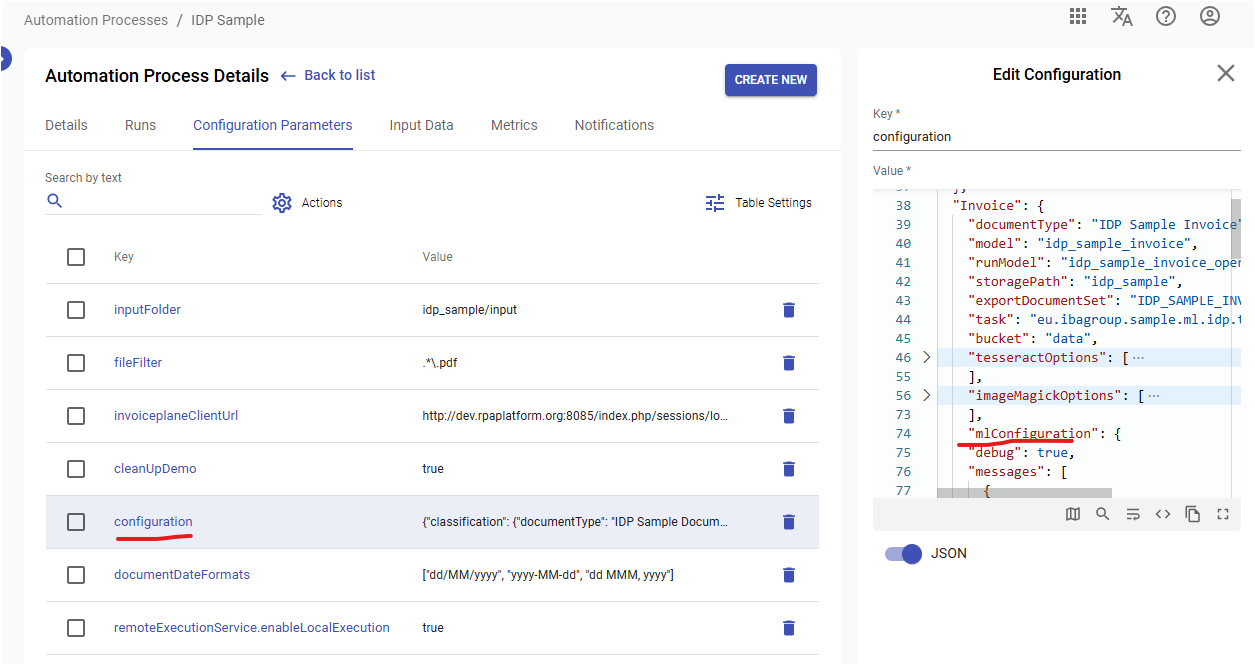
Or in the configuration parameter of AP that uses datastore document context:
The messages parameter defines a promt structure for OpenAI request. Here is models python code that call OpenAI:
client = OpenAI() prompt_completion = client.chat.completions.create( model=openai_model, messages=messages, temperature=0, ) openai_response = str(prompt_completion.choices[0].message.content)
The default messages structure is required, here is default structure:
{
"messages": [{
"role": "system",
"content": "{systemRolePrompt}"
}, {
"role": "user",
"content": "{userRolePrompt}"
}
],
}It sends request with system ( {systemRolePrompt} ) and user ( {userRolePrompt} ) roles. The {systemRolePrompt} and {userRolePrompt} are refers to keys from the promts configuration.
Only one level key references are allowed in the promts configuration.
The html key is injected by the model and contains minified document.
You can completlly change the default messages structure, or redefine the systemRolePrompt and userRolePrompt.
The userRolePrompt always need to be changed according to your document set and fields you need to extract. It contains field description to extract for OpenAI.
HOCR to HTML rendering configuration
The hocr2html parameters specify a simplified text rendering algotitm, that is defined by hocr2html.type key. There are the following rendering exist:
- default - put word in a order htat is exist in HOCR
- table - put words according to recognized table layout
- table-rows - using table render to obtain table layout and put words according to rows flow, without cells separation
Default HOCR to HTML rendering (default)
The default rendering uses the HOCR tags normal ordering to provide output with the following rules:
- <div class="ocr_page"> → <p>
- <span class="ocr_line"> → <div>
- <span class="ocrx_word"> → <span id="word_[Page index]_[Word index on page]">[Word]</span>
Here is a typical rendered html:
<html> <body> <p> <div><span id="word_0_1">Remittance</span><span id="word_0_2">Advice</span></div> <div><span id="word_0_3">Company:</span> <span id="word_0_4">IBA</span><span id="word_0_5">Group</span></div> <div><span id="word_0_6">Income</span><span id="word_0_7">Fund</span></div> </p> <p> <div><span id="word_1_1">ACCOUNTS</span><span id="word_1_2">BALANCE</span></div> <div><span id="word_1_3">12341234</span><span id="word_1_4">$5000</span></div> <div><span id="word_1_5">22354123</span><span id="word_1_6">$1000</span></div> </p> </body> </html>
Table HOCR to HTML rendering (table)
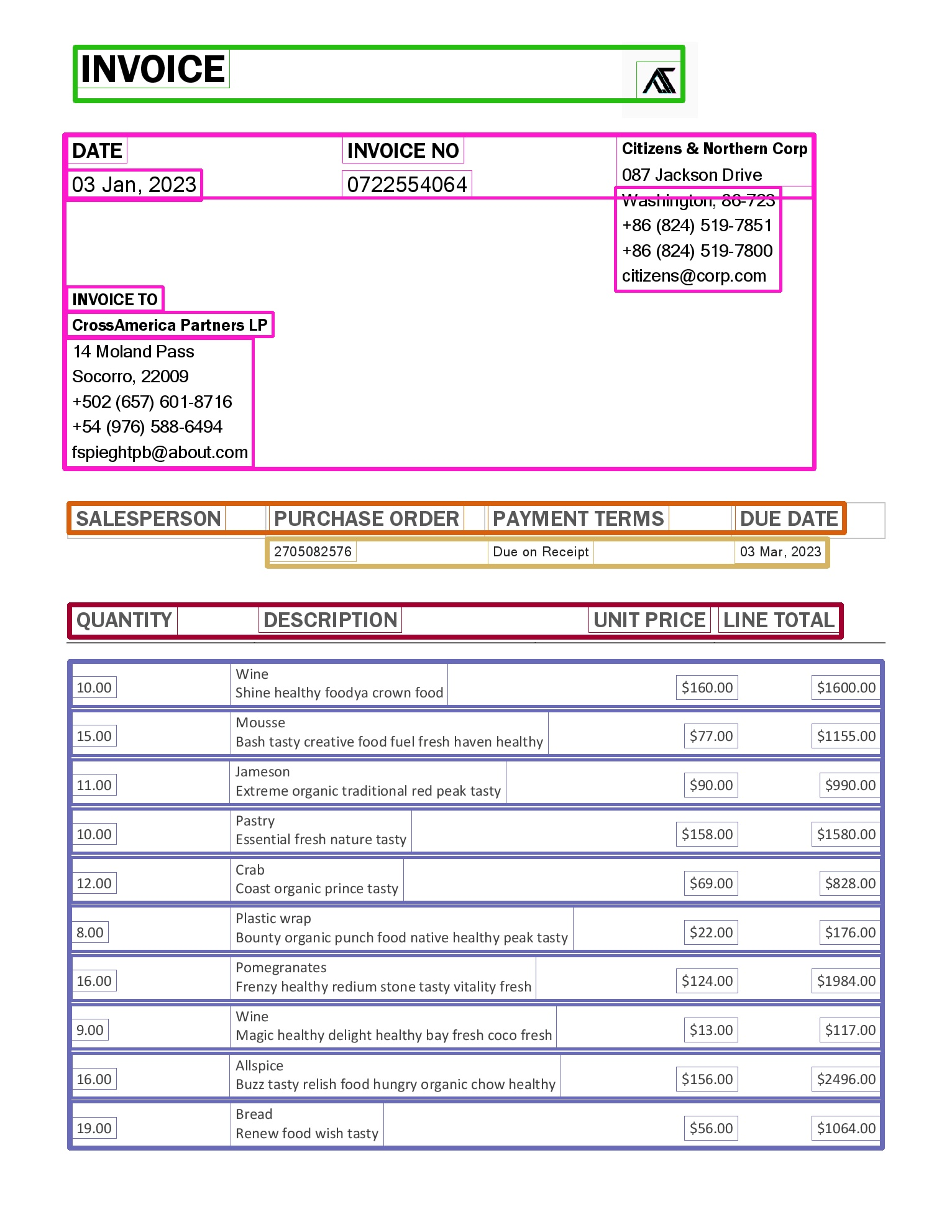
This renderer groups HOCR bboxes into cells,rows and tables like on the following pictures:
The renderer uses the following settings:
"hocr2html": {
"type": "table",
"bbox_to_cell_tolerance_x": 10,
"bbox_to_cell_tolerance_y": 10,
"cell_to_row_tolerance": 20,
"row_to_table_tolerance": 10
},Where:
- bbox_to_cell_tolerance_x - a max width in pixels between 2 bboxes that are belongs to a same table cell
- bbox_to_cell_tolerance_y - a max height in pixels between 2 bboxes that are belongs to a same table cell
- cell_to_row_tolerance - a max height in pixels between 2 cells that are belongs to a same row
- row_to_table_tolerance- a max height in pixels between 2 rows that are belongs to a same table
The renderer do the following:
- tries to combine bboxes into cells using bbox_to_cell_tolerance_x and bbox_to_cell_tolerance_y
- then combines cells into rows using cell_to_row_tolerance
- then combines rows into tables using row_to_table_tolerance
- renders words according to cell order
The debug=true upload to storage a debug JPG with table layout:
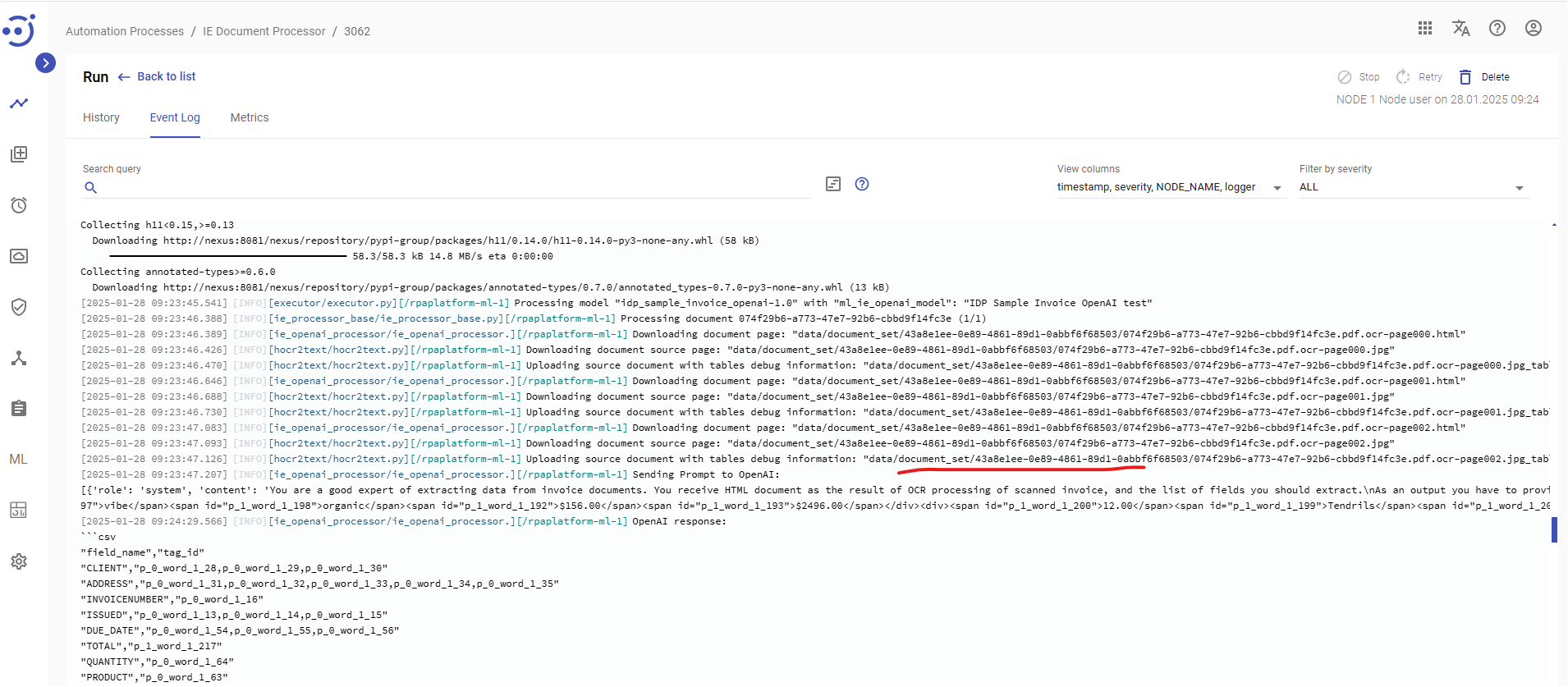
It saves page elements:
- <div class="ocr_page"> → <p>
Here is a typical rendered html:
<html> <body> <p> <table> <tr> <td> <span id="word_0_3">DATE</span> </td> <td> <span id="word_0_13">08</span> <span id="word_0_14">Mar,</span> <span id="word_0_15">2020</span> </td> <td> <span id="word_0_4">INVOICE</span> <span id="word_0_5">NO</span> </td> <td> <span id="word_0_16">4453074013</span> </td> <td> <span id="word_0_6">Park</span> <span id="word_0_7">City</span> <span id="word_0_8">Group</span> <span id="word_0_9">DC</span> <span id="word_0_10">087</span> <span id="word_0_11">Jackson</span> <span id="word_0_12">Drive</span> <span id="word_0_17">Washington,</span> <span id="word_0_18">86-723</span> <span id="word_0_19">+86</span> <span id="word_0_20">(824)</span> <span id="word_0_21">519-7851</span> <span id="word_0_22">citizens@corp.com</span> </td> </tr> </table> </p> </body> </html>
Table-Rows HOCR to HTML rendering (table-rows)
This renderer uses the same table page grouping mechanizm as table redering, but instead of puting <table> into result html, fill out only rows without cell groupping:
- <div class="ocr_page"> → <p>
- row → <div>
- <span class="ocrx_word"> → <span id="word_[Page index]_[Word index on page]">[Word]</span>
Here is a typical rendered html:
<html> <body> <p> <div> <span id="word_0_1">INVOICE</span> </div> <div> <span id="word_0_48">QUANTITY</span> <span id="word_0_49">DESCRIPTION</span> <span id="word_0_50">UNIT</span> <span id="word_0_51">PRICE</span> <span id="word_0_52">LINE</span> <span id="word_0_53">TOTAL</span> </div> <div> <span id="word_0_54">19.00</span> <span id="word_0_55">Initation</span> <span id="word_0_56">crab</span> <span id="word_0_57">meat</span> <span id="word_0_60">Mountain</span> <span id="word_0_61">food</span> <span id="word_0_62">magic</span> <span id="word_0_63">healthy</span> <span id="word_0_64">yummy</span> <span id="word_0_65">food</span> <span id="word_0_58">$150.00</span> <span id="word_0_59">$2850.00</span> </div> </p> </body> </html>
Langfuse integration
The OpenAI models also supports Langfuse integration, where you can track you LLM request and pricing:
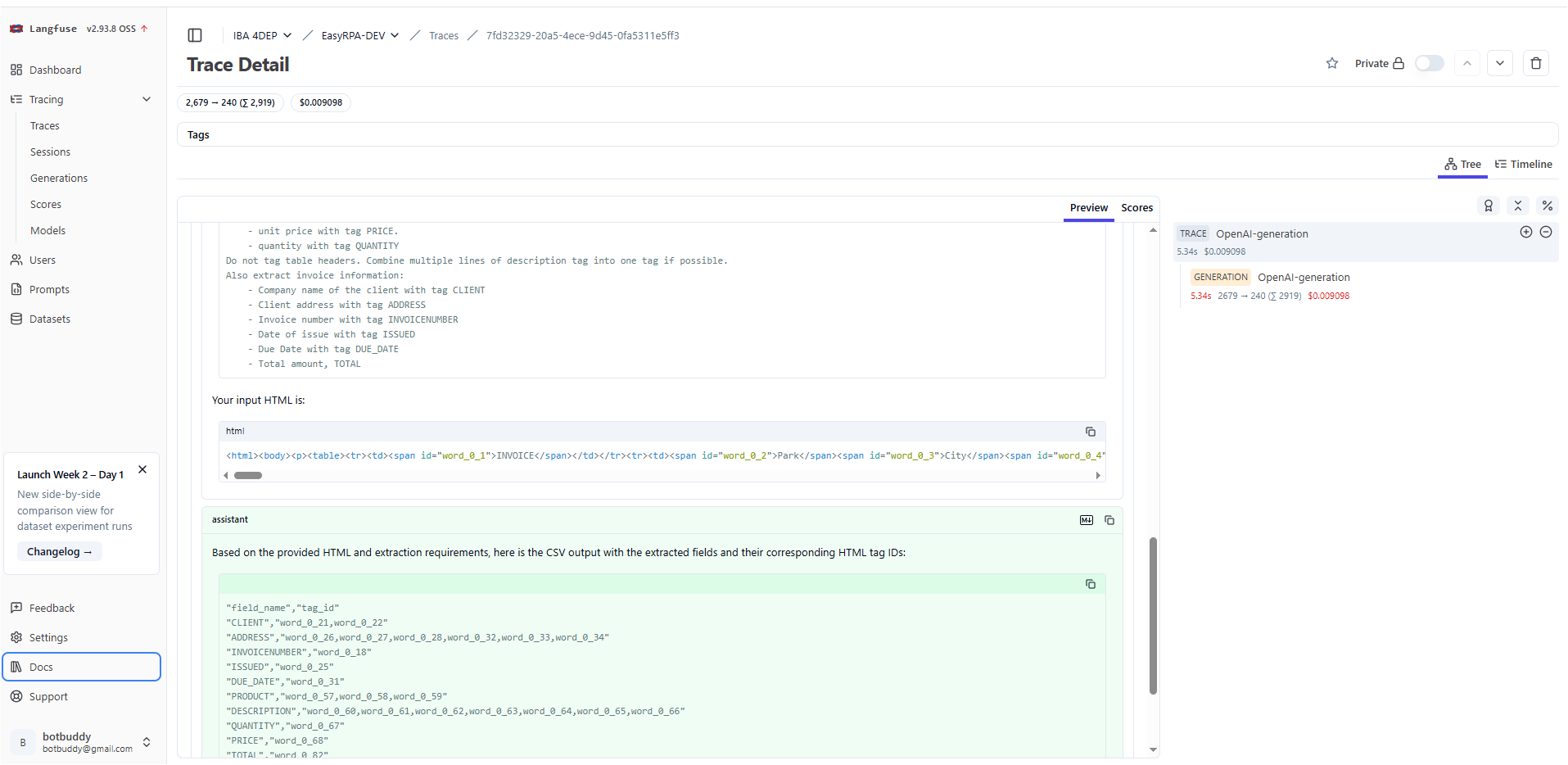
For this you should specify the LANGFUSE_HOST, LANGFUSE_PUBLIC_KEY, LANGFUSE_SECRET_KEY environment variables:
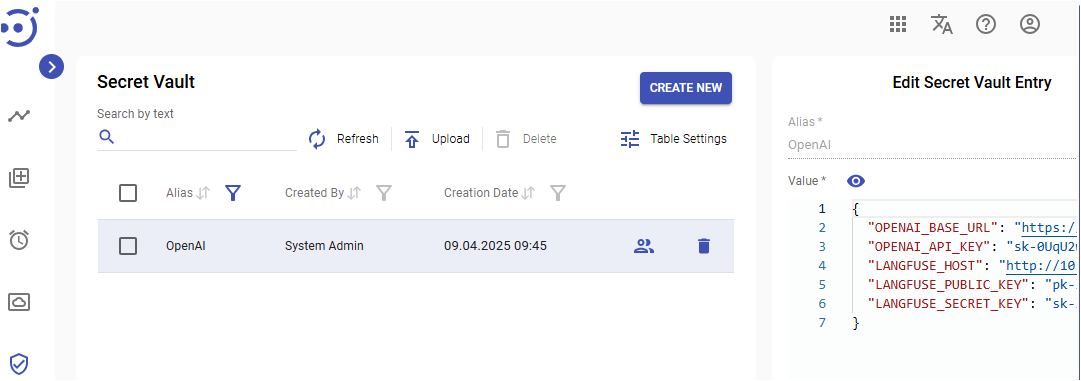
Here is the JSON template for it:
{
"OPENAI_BASE_URL": "https://a_llm_host.org",
"OPENAI_API_KEY": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"LANGFUSE_HOST": "http://10.25.64.83:3000",
"LANGFUSE_PUBLIC_KEY": "pk-lf-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"LANGFUSE_SECRET_KEY": "sk-lf-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
}Sample
The Intelligent Document Processing (IDP) contains document set IDP_SAMPLE_INVOICE_OPENAI that configured to work with the ml_ie_openai_model
Batch API integration
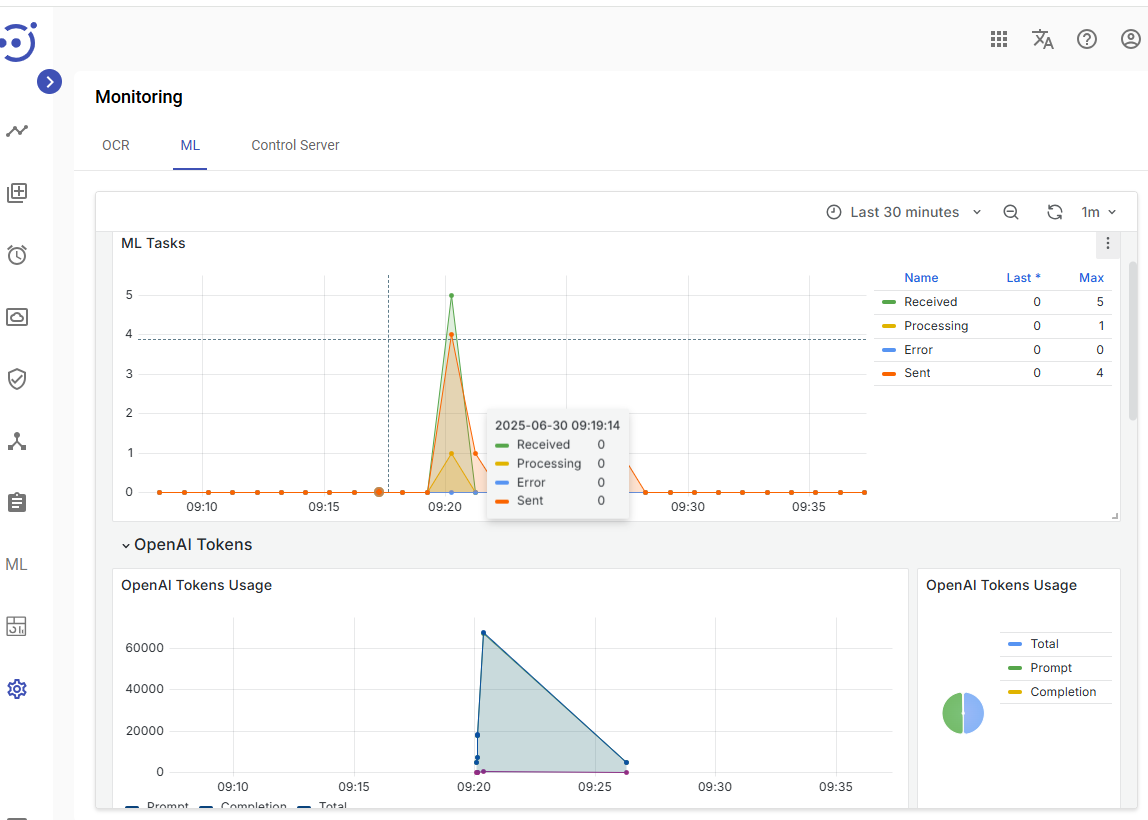
The OpenAI models has posibility to call LLM model asynchronously using OpenAI batch API. It allows to save money using less expensive tokens for document processing when SLA is within 24h.
The model obtain a ML task, perform LLM request using batch API, and waits till it completes, and responses only that is ready in LLM. From automation Process execution perspective, it increases ML task execution till batch_api_completion_window.
The ML monitoring view allows to check such posponding tasks:
ml_iehtml_openai_model
The model has very similar functionality as the ml_ie_openai_model. The difference are in the HTML to minified HTML rendering and default prompts. Here is a default request that model sends to OpenAI:
You are a good expert of extracting data from HTML documents. You receive HTML document and the list of fields you should to extract.
The provided document contains tags with id attributes, you should find the requested fields as text and provide a csv csv file with tree columns:
field_name - the field name
area_id - the id attribute value of a closes tag where the requested field has been found, the only one id should be specified, noticed that not all tags contains the id attribute, the closes parent with id should be used
text - the exact text value of the requested field, the column value could contain less text than the closes tag
Pay attention that one extracted field could has been found in many places.
For table items provide a separate line for each row.
For example:
###BEGIN OF EXAMPLE
User ask you to extract:
```
Find all accounts in the balance sheet and for each item found extract:
- company name with tag COMPANY
- account with tag ACCOUNT
- balance with tag BALANCE
Do not tag table headers.
```
Your input HTML is:
```html
<html>
<body>
<p id="6">
<span id="0">Remittance Advice</span>
<span id="1">Company: IBA Group</span>
<span id="2">Income Fund</span>
</p>
<p id="7">
<span id="3">ACCOUNTS BALANCE</span>
<span id="4">12341234 $5000</span>
<span id="5">22354123 $1000</span>
<span>34567890 $200</span>
</p>
</body>
</html>
```
Your answer always should be a only valid csv file without any comment, do not ommit headers, always use " for values escaping:
```csv
"field_name","area_id","text"
"COMPANY","1","IBA Group"
"ACCOUNT","4","12341234"
"BALANCE","4","$5000"
"ACCOUNT","5","22354123"
"BALANCE","6","$1000"
"ACCOUNT","7","34567890"
"BALANCE","7","$200"
```
###END OF EXAMPLE
Now your task is the following:
```
Find all items in the invoice and for each item found extract:
- item name with tag PRODUCT. If there is no item in the invoice, split the description into item and description: where item it is the first sentence in the description
- description with tag DESCRIPTION
- unit price with tag PRICE.
- quantity with tag QUANTITY
Do not tag table headers. Combine multiple lines of description tag into one tag if possible.
Also extract invoice information:
- Company name of the client with tag CLIENT
- Client address with tag ADDRESS
- Invoice number with tag INVOICENUMBER
- Date of issue with tag ISSUED
- Due Date with tag DUE_DATE
- Total amount, TOTAL
```
Your input HTML is:
```html
{html}
```
Model Training
Here is the models default training config:
where:
- prompts_config - the default prompts configuration saved into trained model
- messages - a prompt messages structure to use during sending to OpenAI API
- html - the document simplified html that model creates and injected into prompt context
- environment - a secret vault aliace where stored JSON with environment variables to set, before call the LLM API
temperature - the request temperature, depends of LLM model, ussually can be gradated like: Coding / Math - 0.0; Data Cleaning / Data Analysis 1.0; Creative Writing / Poetry - 1.5
- open_ai_model - an OpenAI model to use, required
- track_into_langfuse - track the OpenAI conversation into Langfuse if true
- entities- an entity to response tag mapping to map OpenAI tagged document into documents entities. The single flag is using to process concat_single_entities.
- debug - boolean switches debug messages on
- concat_single_entities (boolean)(optional) - This flag uses entities configuration to concatinates entities with the same name into one string.
- elements_with_id - selector for the html element to mark with id
elements_to_delete - selector for the elements to delete from xml
elements_to_unwrap - selector for the elements to unwrap
HTML to minified HTML rendering
Here is a sample of a document minification:
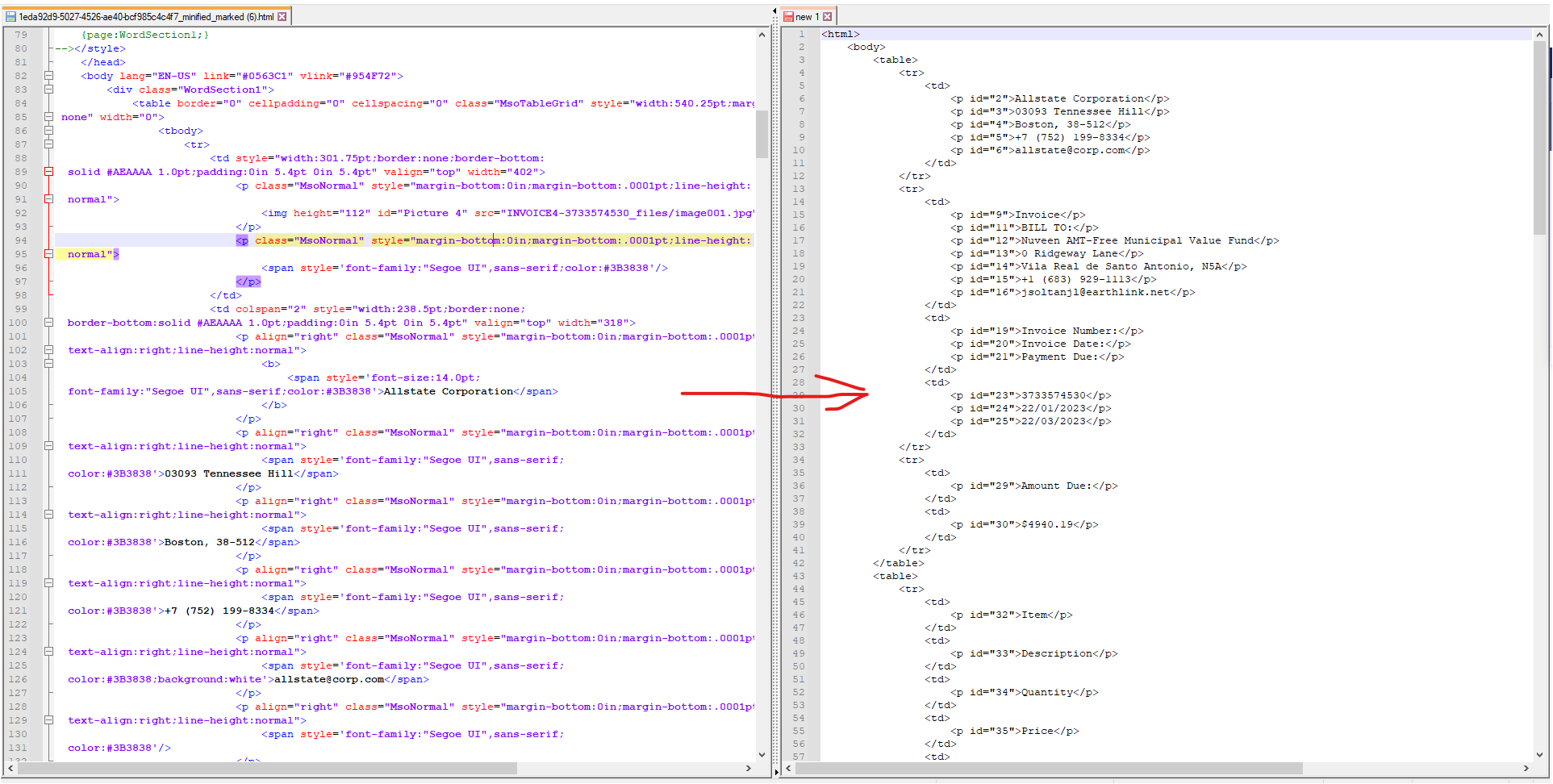
The rendering algotitm is the following:
- add id attribute to the all elements specified by the elements_with_id selector
- delete all elements specified by the elements_to_delete selector
- unwrap all elements specified by the elements_to_unwrap selector
- remove all empty elements
Sample
The Information Extraction HTML Sample contains document sets IE_HTML_OPENAI SAMPLE and IE_HTML_LOAN_OPENAI_SAMPLE that configured to work with the ml_iehtml_openai_model.
The Information Extraction TEXT Sample contains document set IE_TEXT_OPENAI SAMPLE that configured to work with the ml_iehtml_openai_model.
Custom IE Models
The custom models are provided as already trained (do not support training process), so it name/version should be used for extraction process. Curentlly platform has the following custom IE models:
- ml_ie_finext_model - uses hOCR source base
- ml_signature_detection_yolo5_model - uses hOCR source base
- ml_qrcode_detection_model - uses hOCR source base
The custom model do not support training, so they are not listed in the trainer list. If you try to train a model using theier name as trainer it will bring a training error.
ml_ie_finext_model
The purpose of the process is to extract the following basic financial information from documents using the rule-based model:
- Country references (full names and codes ISO 3166)
- Currency references (full and codes ISO 4217)
- IBANs
- Swift codes
- Numbers and amounts (in digital format and written in text)
- Email addresses
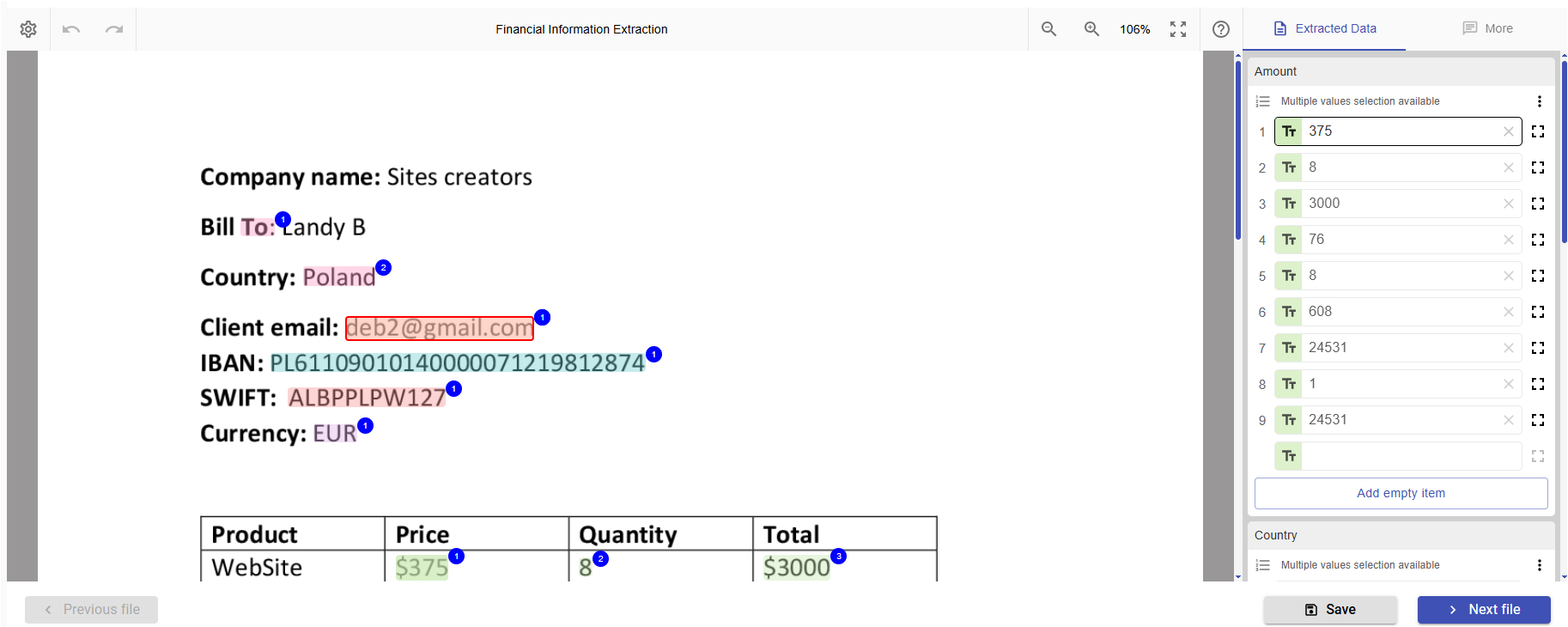
Extracting entities
Country
The model includes a .csv file config_countries.csv with short abbreviations and possible full titles, for example:
- US,United States of America
- US,United States
- US,USA
- US,U.S.A
The processor extracts all instances of the short or full name.
Currency
The model includes a .csv file config_currencies.csv with pairs of abbreviations and short or full names, as follows:
- US Dollar,USD
- $,USD
The processor extracts all instances of the short/full name or abbreviation.
IBAN
IBAN values are extracted by regular expression and validated by IBAN length from iban_countries_length.csv config_iban_countries_length.csv (different countries have different lengths)
SWIFT
SWIFT values are extracted by regular expression.
Amount
Model extracts numbers and numerals that can be amounts. Examples:
- 3,000,000.00
- 5.000
- two hundred twenty five
- one thousand and four
Emails are extracted by regular expression.
Sample
Refer to the Financial Information Extraction Sample Process (FinextSample) for details.
ml_signature_detection_yolo5_model
Detects any signature present on the page. It provides entity with name Signature (if page contains any signature) in the response entity:

Sample
Refer to the Signature Detection & Recognition for details.
ml_qrcode_detection_model
Recognizes any BAR/QR codes present on the page. It provides entity with name QRCODE (if page contains any signature) in the response entity:
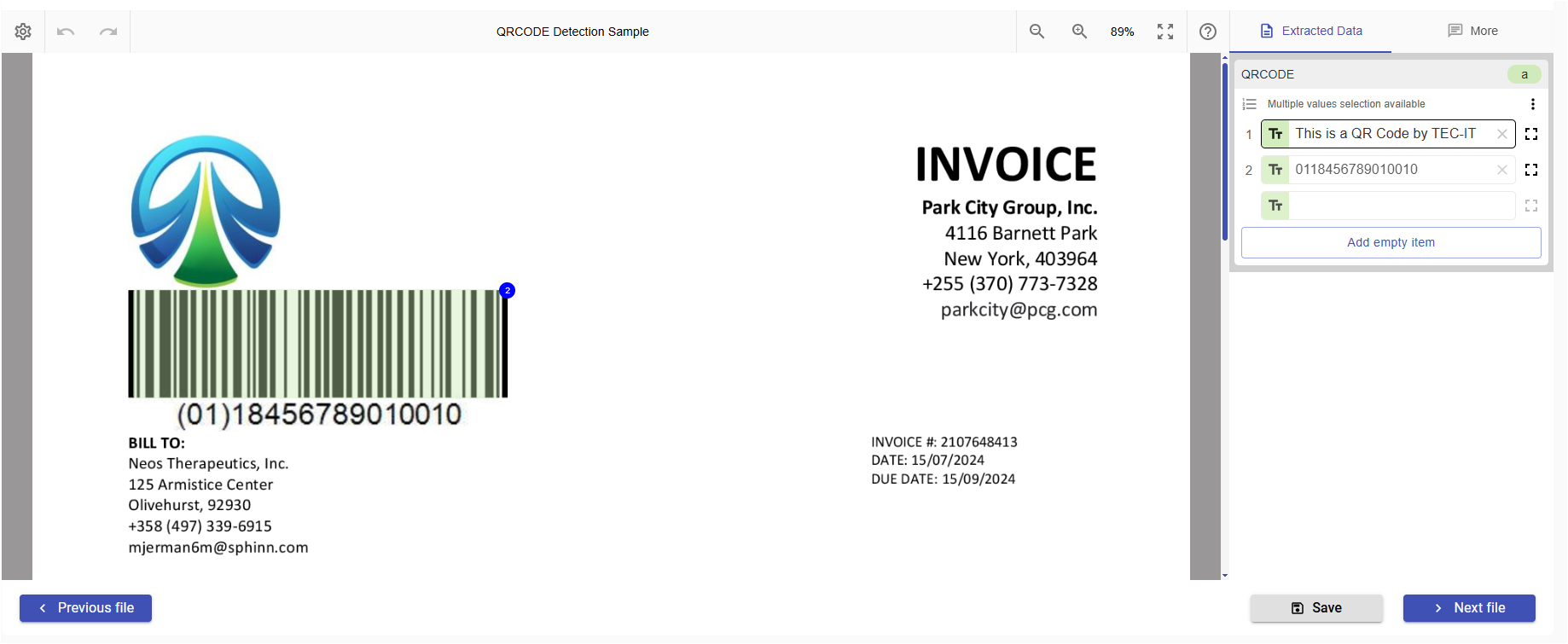
The model uses pyzbar libriary and supports the folowing BAR/QR code formats:
- GS1 2-digit add-on
- GS1 5-digit add-on
- EAN-8
- UPC-E
- ISBN-10 (from EAN-13)
- UPC-A
- EAN-13
- ISBN-13 (from EAN-13)
- EAN/UPC composite
- Interleaved 2 of 5
- GS1 DataBar (RSS)
- GS1 DataBar Expanded
- Codabar
- Code 39
- PDF417
- QR Code
- SQ Code
- Code 93
- Code 128
Sample
You can upload the following package from the platform nexus to play with the model:
Group Id: eu.ibagroup.samples.ap
Artifact Id: easy-rpa-ml-ap
Version Id: <EasyRPA version>
Document Set: QRCODE_DETECTION_SAMPLE