Information Extraction process
Information Extraction process
This article covers the end-to-end process of developing Information Extraction (IE) automation and contains 2 sections:
From the high-level perspective, the IE automation process looks like on the diagram below and it should process all records asynchronously in parallel:
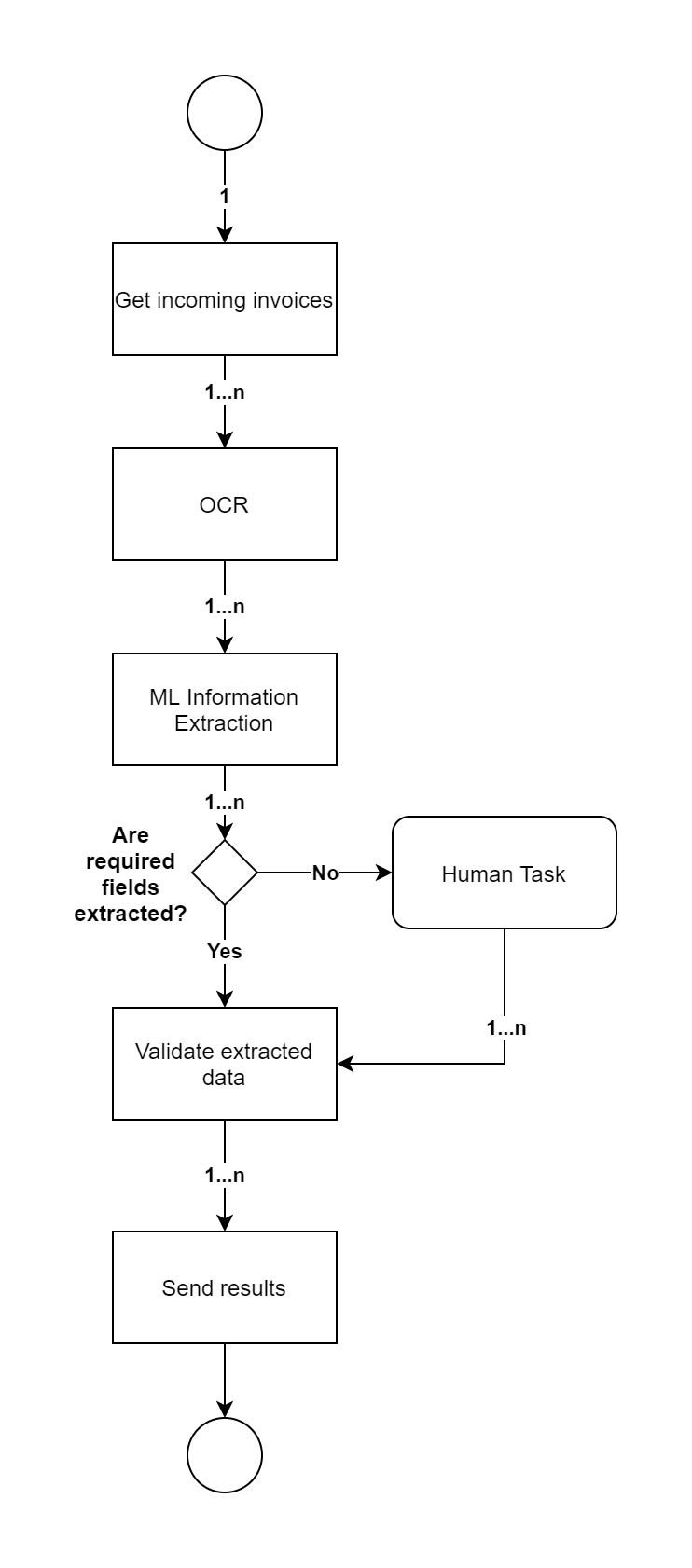
Analyze the document type to decide the next steps
Depends on the file format of your incoming documents, there're different ways we suggest working with it.
In the table below you may see 2 different suggested approaches:
- Machine Learning - if you decided to go with this approach, you can continue following this guide.
- Rule-based - if you decided to go with a rule-based approach - you can skip the next steps of this guide and implement the suggested way to extract valuable information from documents.
| Document file format | Suggest approach | Comment |
|---|---|---|
| Machine Learning | PDF documents can be categorized in three different types, depending on the way the file originated. How it was originally created also defines whether the content of the PDF (text, images, tables) can be accessed or whether it is “locked” in an image of the page. 1.“True” or Digitally Created PDFs Digitally created PDFs, also known as “true“ PDFs, are created using software such as Microsoft® Word, Excel® or via the “print” function within a software application (virtual printer). They consist of text and images. 2. “Image-only” or Scanned PDFs When scanning hard copy documents on MFPs and office scanners, or when converting a camera image, jpg, tiff or screenshot into a PDF, the content is “locked” in a snapshot-like image. Such image-only PDF documents contain just the scanned/photographed images of pages, without an underlying text layer. Consequently, image-only PDF files are not searchable, and their text usually cannot be modified or marked up. An “image-only” PDF can be made searchable by applying OCR with which a text layer is added, normally under the page image. 3. Searchable PDFs Searchable PDFs usually result through the application of OCR (Optical Character Recognition) to scanned PDFs or other image-based documents. During the text recognition process, characters and the document structure are analyzed and “read”. A text layer is added to the image layer, usually placed underneath. Such PDF files are almost indistinguishable from the original documents and are fully searchable. Text in searchable PDF documents can be selected, copied, and marked up. Processing pdf workflow depends on type of PDF. In case of Searchable (case 3) or "True" PDFs (case 1) we can get content of the files using pdfbox apache library. "Image-only" PDFs (case 2) should go through OCR step at first. | |
| Image | Machine Learning | This type of documents usually comes as scans. Typical workflow for images is the following:
|
| Excel | Rule-based | Both approaches (ML and Rule-based) can be applied for this type of document, but generally it is much easy to implement rules-based approach cause excel is structured document. Keep in mind that you should convert excel to html before sending the document to Manual Task |
| HTML | Rule-based | For html files we also can go with both approaches (ML and Rule-based). Please be aware that if customer has well structured HTML format probably the best solution is to use xpath to extract data from documents Only in case of you don't know the structure of HTML, you should use ML approach. Usually it happens when you need to extract the data from not auto generated email body by itself, as people write email without any predefined template. |
| Plain Text | Machine Learning | ML approach is preferred for this format, but rule-based also can be applied (for example we 100% sure that invoice number is the first word in the document). Please note that plain text is the worth case for the ML approach cause this format does not have any additional information (like html tags). |
| Other formats | You may encounter other types of documents. Review the structure of the documents to make the right decision on the use of the approach |