Tackling Unstraight Text Lines
Tackling Unstraight Text Lines
The most commonly used PSM (Page Segmentation Mode) in Tesseract OCR when processing text images is --psm 3 (Auto mode with OSD). This mode is often preferred for general text recognition tasks because it performs automatic page segmentation and layout analysis with OSD, adapts to different text regions within the image. It was also designed to handle a wide range of text images, including those with varying layouts, fonts, sizes, and alignments. However, the choice of the mode depends on the specific characteristics of the text image, such as the presence of tables, columns, or other structural elements. In some cases, other PSM modes like --psm 6 (Assume a single uniform block of text) or --psm 11 (Sparse text) might be more suitable. It's recommended to experiment with different PSM options to find the optimal mode for your particular OCR task.
In the example below the text image contains a table where text lines within table rows are not straignt.
- --psm 3 (Auto mode with OSD):
The order of numbers in the output file is influenced by various factors, including the positioning of text blocks, line heights, and other layout information detected by Tesseract.
When the table lines are not very straight, the layout analysis might interpret the text blocks in a way that results in numbers being ordered based on their vertical position in the row. This can occur due to variations in line heights caused by the non-straight table lines. Since the lines in the image are not aligned in a regular manner, the numbers are recognized in a different order.
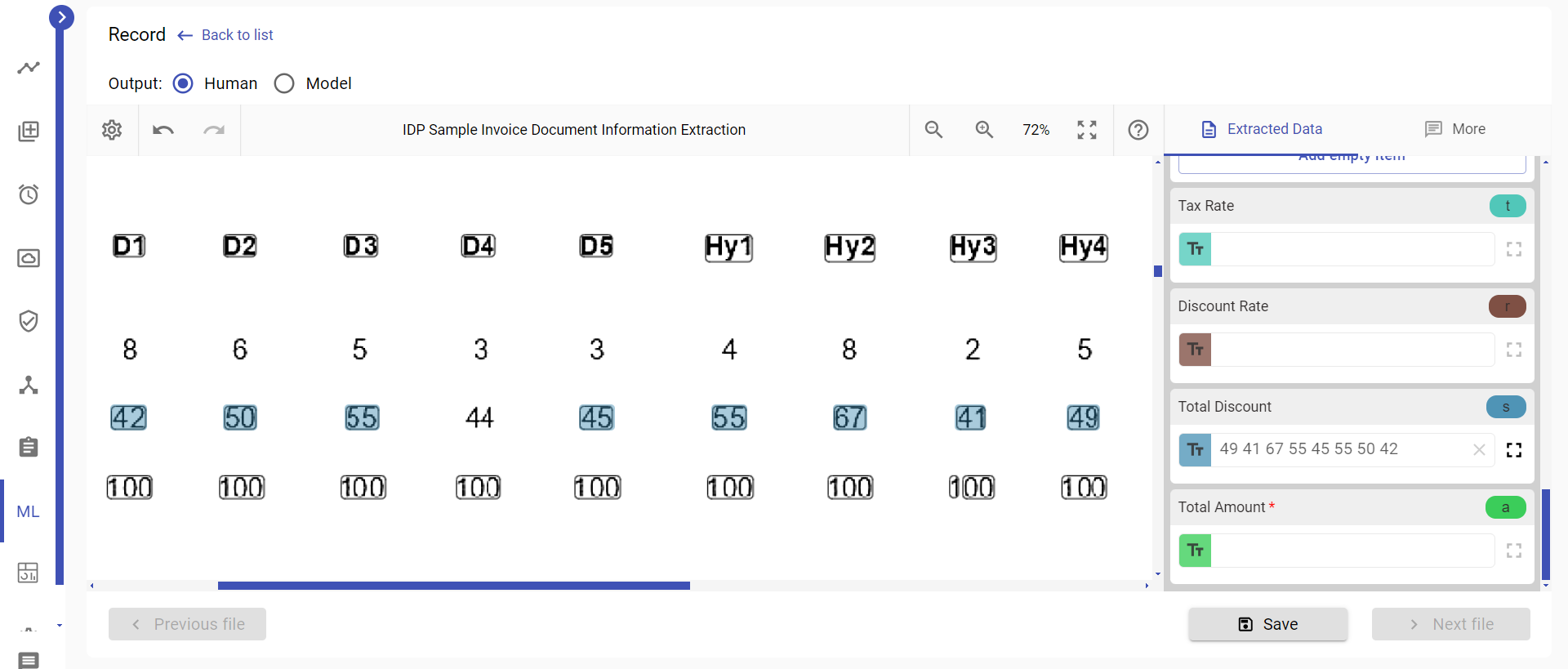
- --psm 6 (Assume a single uniform block of text):
In this mode, Tesseract treats the entire image as a single block of text without performing extensive layout analysis or considering the table structure explicitly. The numbers from the table rows appear in the output file in the exact order they are present in the rows because --psm 6 assumes a single uniform block of text, disregarding any structural information or variations in line heights caused by non-straight table lines.
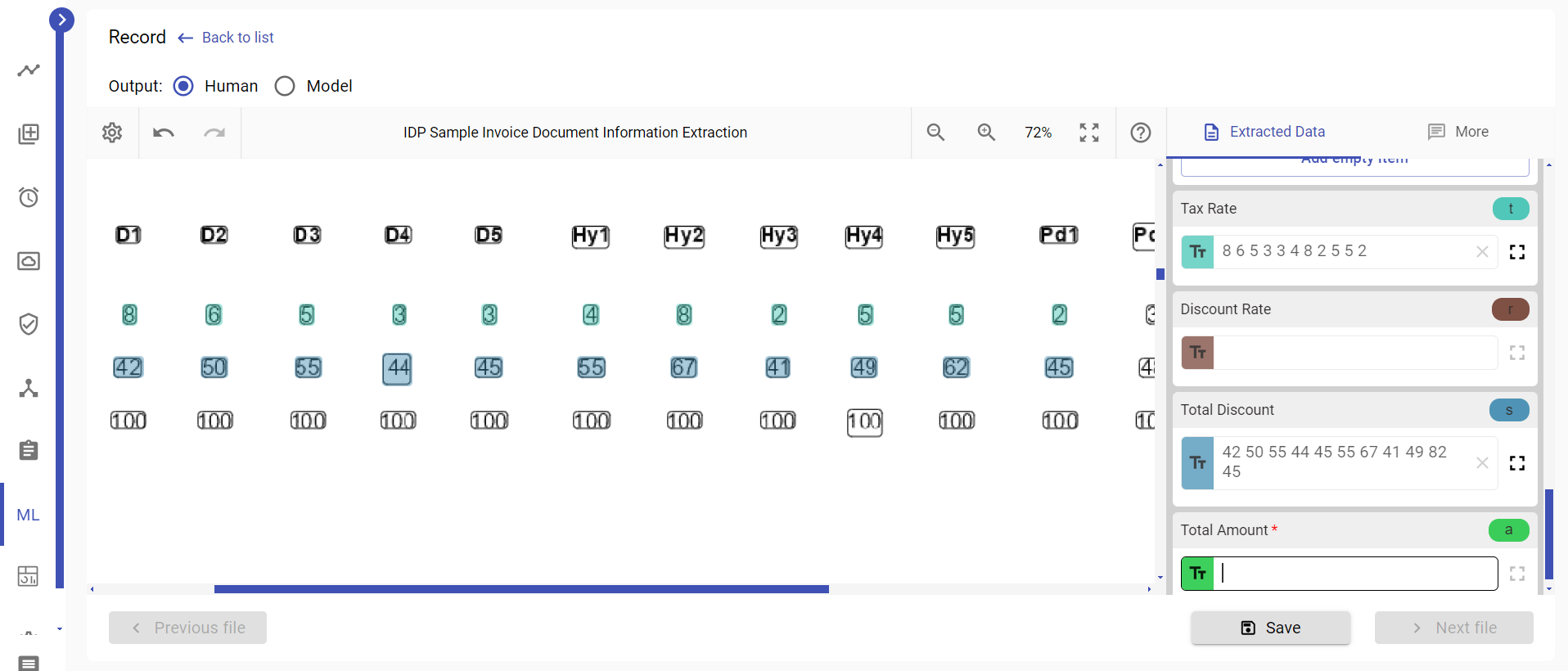
Therefore in this particular case --psm 6 mode is preferable. It produces correct order of numbers in the table rows as output since it is based solely on the sequential order of text encountered. It also allows for more accurate text recognition for this particular text image.
To read more about PSM modes. see OCR Analysis.