Terminology
Terminology
A
Accuracy
Accuracy is one metric for evaluating classification models. Informally, accuracy is the fraction of predictions our model got right. Formally, accuracy has the following definition:
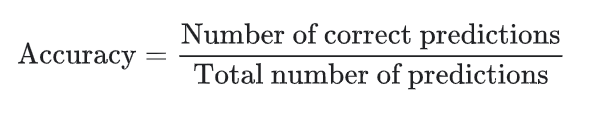
For binary classification, accuracy can also be calculated in terms of positives and negatives as follows:
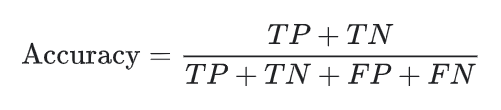
where TP = True Positives, TN = True Negatives, FP = False Positives, and FN = False Negatives.
C
Classification
Classification – the task of predicting class for the items.
D
Data Analyst (DA)
Dedicated role during delivery of automation projects which include unstructured data processing. A person with DA skills will be in charge of appropriate documents selection, processing, structure and input for model training. Because the overall success of ML implementation highly depends on the quality of input, this role is crucial.
Data value
The value of the tagged string
Document type
Type of document that is processed in the Use Case (Information Extraction, Classification) depending on the industry (statement of value, invoice, email, purchase order, loan booking, reconciliation, annual reports, etc.).
Data labeling
The process of assigning a "label" to a particular value in the text or on the picture, e.g.: "Apple" for company_name, "25, High Falls" for address, etc.
For Information Extraction Use cases, labeling can be referred to as tagging.
E
Elements
Elements – units that are created while documents pass through the pipeline. Elements are represented as tokens, tables, sentences, pages, Named Entities, or Entity Boundary Elements and are used in content analysis. Some elements are created based on tags from manual labeling, while others - as a result of analysis of words, phrases, named entities in unstructured content.
F
False negative (FN)
Type of mistake: value should be extracted but the model has extracted nothing (for Information Extraction use case).
False positive (FP)
Type of mistake: no value should be extracted, but the model has extracted something (for Information Extraction use case).
Feature
Feature – a property of element being evaluated. Generally feature is a simple question with a Yes/No answer which is used by the ML algorithm to predict which tokens should be tagged as correct answers.
Fields
Fields – attributes that should be extracted from the documents (for example date, email, company name, company address).
FP/FN
Type of mistake: value should be extracted, but the model has extracted this value with mistake or value should be extracted, but the model has extracted something different (for Information Extraction use case).
G
Gold data
Data labeled in a manual task by a Data Analyst for SMEs' qualification and then by SMEs for model training and testing.
H
Human task
Human task – a document labelling task performed by human expert (usually SME) in order to provide gold data for model training and evaluation.
I
Information extraction
Information extraction – the task of extracting structured information or key facts from unstructured and/or semi-structured documents. For example, extracting financial information from invoices, claims and other financial documents.
M
ML Engineer (MLE)
The specialist who leads model training, improves and retrains the model when necessary.
Model
Model – an artifact that represents a combination of components, like algorithms and their parameters, annotators, feature extractors, pre- and post-processors, that has been trained to recognize certain types of patterns. Once model is configured, ML Engineer can proceed with model training (i.e. providing it an algorithm that it can use to reason over and learn from those data). Once ML Engineer obtains trained model with proper model results, it can be further used for model execution process.
O
OCR
Optical Character Recognition is the electronic conversion of images of typed, handwritten or printed text into machine-encoded text (EasyRPA uses JSON format).
P
Precision
Precision – metric that is calculated to analyze model results, and defined as the number of items correctly predicted/extracted divided by the total number of predicted/extracted items.
R
Recall
Recall – metric that is calculated to analyze model results, and defined as the number of items correctly predicted/extracted divided by the total number of items that actually belong to the class (gold results).
S
Subject Matter Expert (SME)
A Subject Matter Expert is an individual (from the customer’s side) with a deep understanding of a particular process, function, technology, machine, material or type of equipment who participates in data labeling.
T
Test set
A set of unseen documents used for evaluating the ML model and to test it for possible exception cases in production. Test set composes 20% of the whole data set and is not used for model training.
Token
The smallest elementary element of a document, usually word separated by spaces or other special characters, that can be further used for content analysis.
Training set
A set of documents (invoices, e-mails, contracts, etc.) used for training an ML model. For Information extraction, a training set consists of documents which contain gold values (the values surrounded by special tags) for a set of fields that should be extracted. For Classification, training set consists of documents accompanied by target class.
True negative (TN)
Correct scenario: value should not be extracted and nothing has been extracted by the model (for Information Extraction use case).
True positive (TP)
Correct scenario: value should be extracted, and it is extracted by the model (for Information Extraction use case).