Develop Automation Process (Classification) using Document Processors
Develop Automation Process (Classification) using Document Processors
Preface
For the ML Automation Process we are going to use platform Document Processors a base.
In our step-by-step example we're going to implement EasyRPA Storage scanning for new incoming invoices.
The full completed project can be obtained from the samples GIT https://code.easyrpa.eu/easyrpa/easy-rpa-samples/-/tree/dev/confluence-samples/classification-sample-dp
In the first step, you will need to download the archetype. The following link provides more information on how to do this: Generate project from archetype. In the generated from archetype project, the following should be added to pom.xml:
<dependencies>
. . . .
<dependency>
<groupId>eu.ibagroup</groupId>
<artifactId>easy-rpa-aps</artifactId>
<version>${rpaplatform.version}</version>
</dependency>
. . . .
<dependencies>Second thing we need to do - define configuration for the AP run:
- set datastore name for documents
- set storage path for files
- set run model
- set OCR options
Step 1. OOTB Document Processing
This step is completely the same as for Information Extraction: Step 1. Prepare input documents (IE)
Reuse OOTB code with no flow modification
The Automation Process (AP) class will looks like the following:
package eu.ibagroup.samples.cldp;
import eu.ibagroup.easyrpa.ap.cldp.ClDocumentProcessorBase;
import eu.ibagroup.easyrpa.ap.dp.DocumentProcessor;
import eu.ibagroup.easyrpa.engine.annotation.ApModuleEntry;
import eu.ibagroup.samples.cldp.entity.ClDocument;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
@ApModuleEntry(name = "Classification DP Sample (Step 1)")
@Slf4j
public class InvoiceClassificationSample_1 extends DocumentProcessor<ClDocument> implements ClDocumentProcessorBase {
@Override
public Logger log() {
return log;
}
}The entity, we define new field for future use:
package eu.ibagroup.samples.cldp.entity;
import eu.ibagroup.easyrpa.ap.dp.entity.DpDocument;
import eu.ibagroup.easyrpa.persistence.annotation.Column;
import eu.ibagroup.easyrpa.persistence.annotation.Entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity(value = "CL_SAMPLE_DP_DOCUMENTS")
@ToString
public class ClDocument extends DpDocument {
@Column("category")
private String category;
@Column("score")
private Double score;
}The repository:
package eu.ibagroup.samples.cldp.repository;
import eu.ibagroup.easyrpa.ap.dp.repository.DpDocumentRepository;
import eu.ibagroup.samples.cldp.entity.ClDocument;
public interface ClDocumentRepository extends DpDocumentRepository<ClDocument> {
}The custom postprocessor, to fill entity 'category' and 'score' fields after ML :
package eu.ibagroup.samples.cldp.postprocessors;
import javax.inject.Inject;
import eu.ibagroup.easyrpa.ap.dp.annotation.PostProcessorMethod;
import eu.ibagroup.easyrpa.ap.dp.annotation.PostProcessorStrategies;
import eu.ibagroup.easyrpa.ap.dp.model.ClCategories;
import eu.ibagroup.easyrpa.ap.dp.postprocessing.BasePostProcessor;
import eu.ibagroup.easyrpa.ap.dp.postprocessing.ClPostProcessorBase;
import eu.ibagroup.samples.cldp.entity.ClDocument;
import eu.ibagroup.samples.cldp.repository.ClDocumentRepository;
import lombok.Getter;
@PostProcessorStrategies("classification")
public class StoreClMlResult extends BasePostProcessor<ClDocument> implements ClPostProcessorBase<ClDocument> {
@Inject
@Getter
private ClDocumentRepository documentRepository;
@PostProcessorMethod("storeClMlTaskResults")
public void idpSampleStoreClMlTaskResults() {
log().debug("Storing response from CL ML Task for document {} ", documentContext().getDocumentId());
ClDocument document = documentContext().getDocument();
ClCategories clCategories = getClCategories();
String resultCategory = clCategories.getCategory();
Double resultScore = clCategories.getCategoryScore(resultCategory);
document.setCategory(resultCategory);
document.setScore(resultScore);
}
}The custom validator - to validate number of document pages and send to Human review if document is multi-page:
package eu.ibagroup.samples.cldp.validators;
import javax.inject.Inject;
import eu.ibagroup.easyrpa.ap.dp.annotation.PostProcessorMethod;
import eu.ibagroup.easyrpa.ap.dp.annotation.PostProcessorStrategies;
import eu.ibagroup.easyrpa.ap.dp.model.HocrInputJson;
import eu.ibagroup.easyrpa.ap.dp.postprocessing.BasePostProcessor;
import eu.ibagroup.easyrpa.ap.dp.validation.ClValidatorBase;
import eu.ibagroup.easyrpa.ap.dp.validation.ValidationMessage;
import eu.ibagroup.samples.cldp.entity.ClDocument;
import eu.ibagroup.samples.cldp.repository.ClDocumentRepository;
import lombok.Getter;
@PostProcessorStrategies("classification")
public class ValidateClMlResult extends BasePostProcessor<ClDocument> implements ClValidatorBase<ClDocument> {
@Inject
@Getter
private ClDocumentRepository documentRepository;
@PostProcessorMethod("validateClMlResults")
public void idpSampleValidateInvoiceAmounts() {
if(new HocrInputJson(documentContext()).findPages().size()>1 ) {
addMessages(ValidationMessage.error("Please review classified category for multi-page document"));
}
}
}The document type JSON extended with custom postprocessor and validator definition:
Only with these 5 classes above and a change to document type, a full-featured document processing is ready to be executed.
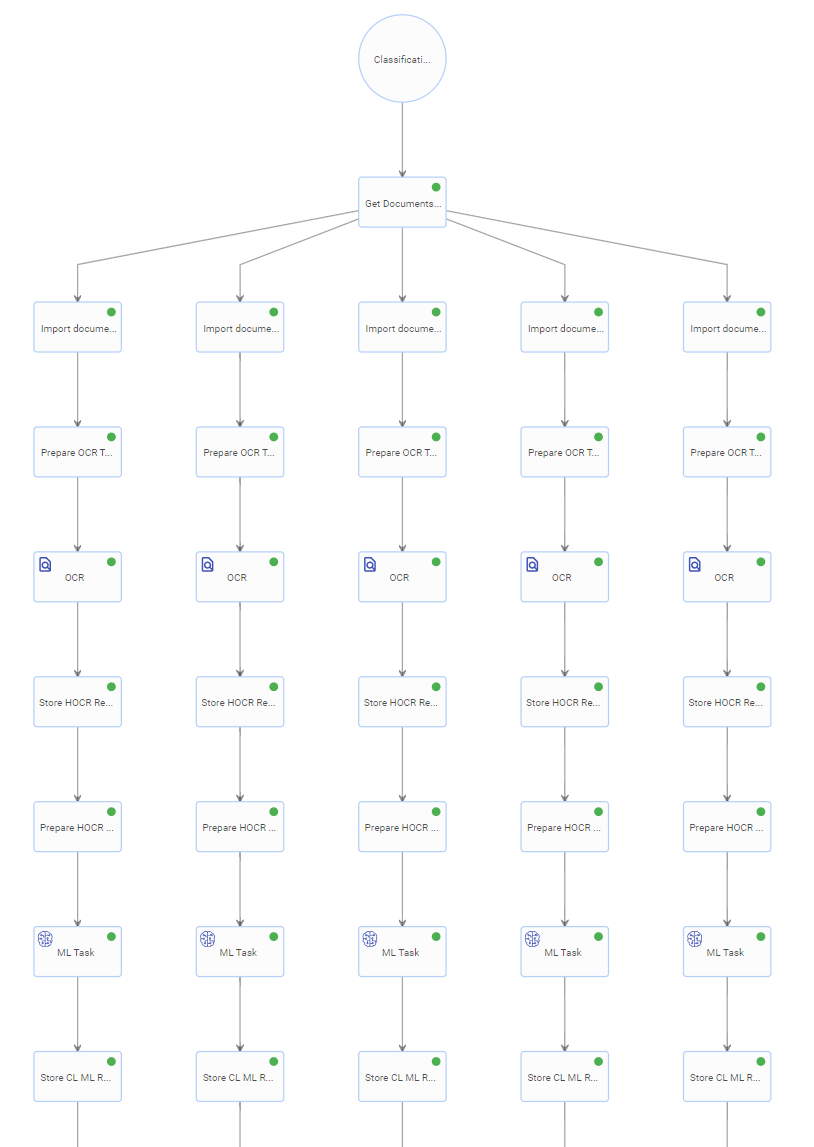
Below are the steps that included into the OOTB classification document processing:
- obtain files from storage
- creates a document record for every file in datastore CL_SAMPLE_DP_DOCUMENT
- OCR the document
- call ML task for document
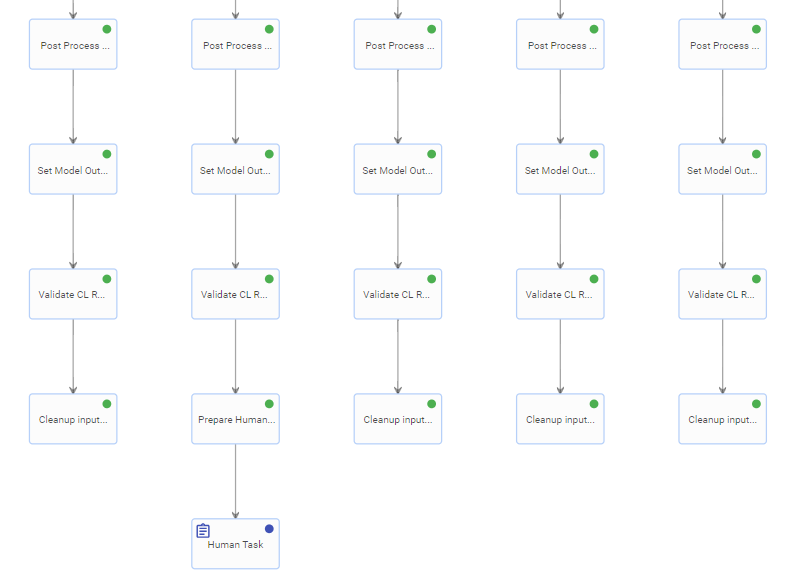
- call postprocessors (if any)
- call validators (the default OOTB one to check score against threshold + custom validators if any)
- call HT for document (if validation failed)
- save all data into document record
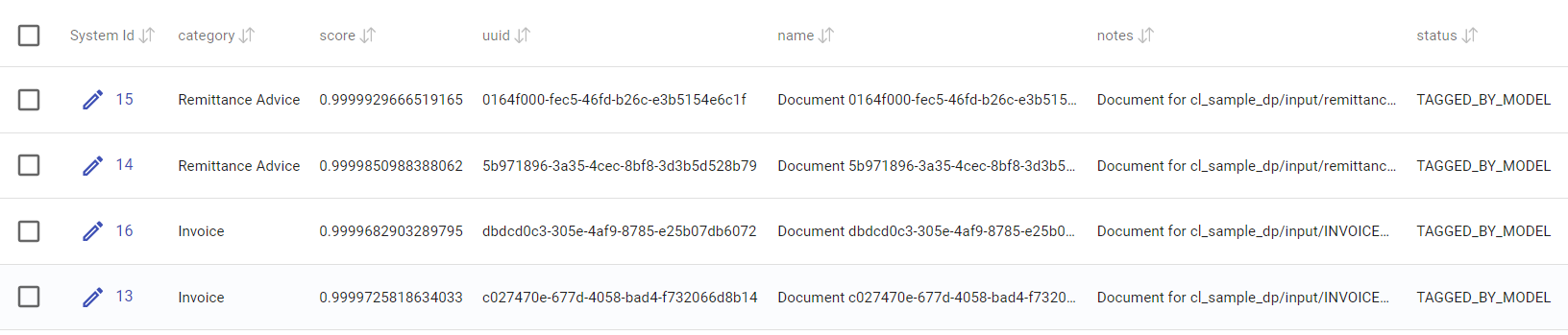
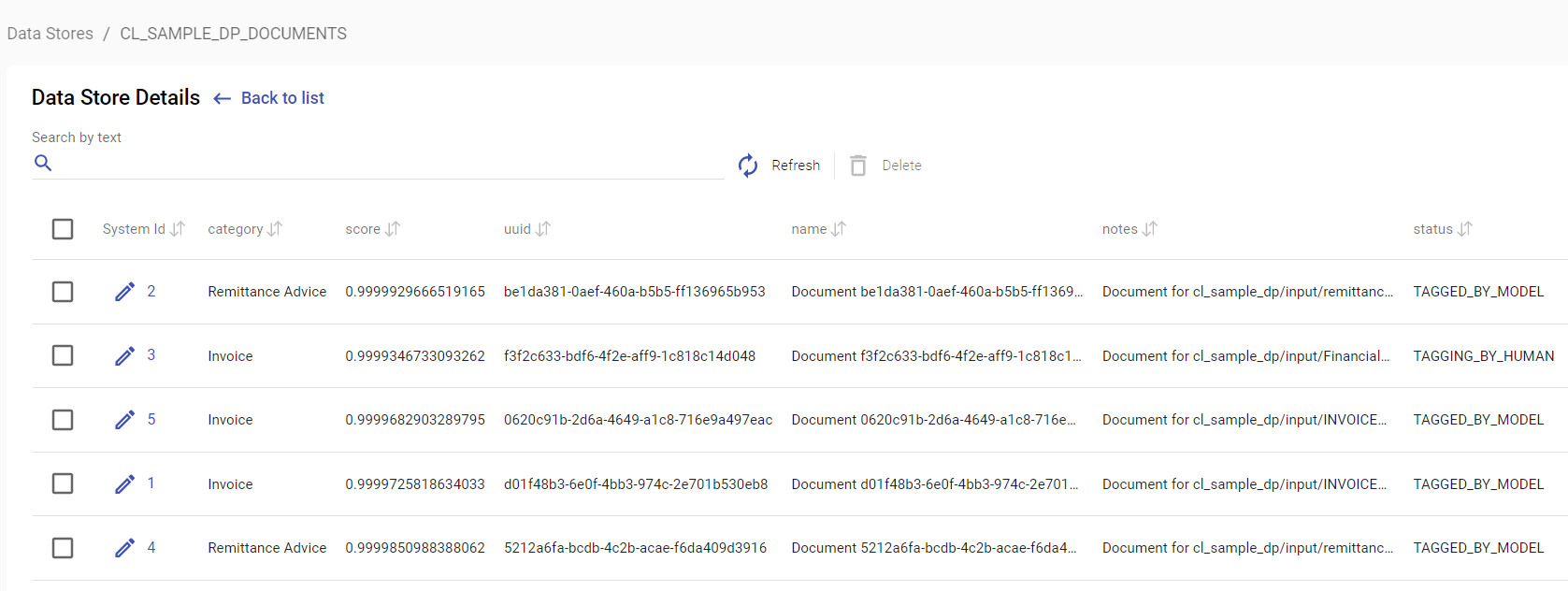
The AP run result:
Step 2. OOTB Modification
This step is completely the same as for Information Extraction: Step 2. OOTB Modification
Let's customize default OOTB Document Proccessing flow - add extra 'GetInvoiceResult' step after ML that persist category and score results into data store:
package eu.ibagroup.samples.cldp;
import eu.ibagroup.easyrpa.ap.cldp.ClDocumentProcessorBase;
import eu.ibagroup.easyrpa.ap.dp.DocumentProcessor;
import eu.ibagroup.easyrpa.engine.annotation.ApModuleEntry;
import eu.ibagroup.easyrpa.engine.apflow.TaskInput;
import eu.ibagroup.easyrpa.engine.apflow.TaskOutput;
import eu.ibagroup.samples.cldp.entity.ClDocument;
import eu.ibagroup.samples.cldp.task.GetResult;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import java.util.concurrent.CompletableFuture;
@ApModuleEntry(name = "Classification DP Sample (Step 2)")
@Slf4j
public class InvoiceClassificationSample_2 extends DocumentProcessor<ClDocument> implements ClDocumentProcessorBase {
@Override
public Logger log() {
return log;
}
@Override
public CompletableFuture<TaskOutput> processDocument(TaskInput docInput) {
return super.processDocument(docInput).thenCompose(execute(GetResult.class));
}
}We are obtaining model output json from document and obtaining result category and score. Here is GetInvoiceResult code:
package eu.ibagroup.samples.cldp.task;
import eu.ibagroup.easyrpa.ap.dp.model.ClCategories;
import eu.ibagroup.easyrpa.ap.dp.tasks.to.ContextId;
import eu.ibagroup.easyrpa.ap.dp.tasks.to.DocumentId;
import eu.ibagroup.easyrpa.ap.dp.validation.ClValidatorBase;
import eu.ibagroup.easyrpa.engine.annotation.ApTaskEntry;
import eu.ibagroup.easyrpa.engine.annotation.InputToOutput;
import eu.ibagroup.easyrpa.persistence.documentset.DocumentSet;
import eu.ibagroup.samples.cldp.entity.ClDocument;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
@ApTaskEntry(name = "Get Classification Result")
@Slf4j
@InputToOutput(value = { ContextId.KEY, DocumentId.KEY })
public class GetResult extends ClDocumentTask implements ClValidatorBase<ClDocument> {
@Override
public Logger log() {
return log;
}
@Override
public void execute() {
ClDocument document = documentContext().getDocument();
ClCategories clCategories = getClCategories();
String resultCategory = clCategories.getCategory();
Double resultScore = clCategories.getCategoryScore(resultCategory);
document.setCategory(resultCategory);
document.setScore(resultScore);
documentContext().updateDocument(DocumentSet.Status.TAGGED_BY_MODEL);
}
}Set the extracted fields into document and save it. The run history has our tasks in the document processing flow: