Collecting Data Set
Collecting Data Set
Data set requirements
To build an effective data set, four core requirements must be met:
- Size:
The size of the data set depends on documents' complexity and variability, and the number of particular documents available. Usually, the approach is to use the data set at a minimum size to achieve sufficient results. The average size of the data set varies among use cases and often numbers 150 - 300 documents. - Representativeness:
The main rule applied is that the data set should reproduce the document flow in production. This means the data set should contain the same distribution of different documents' types and subtypes (usually referred to as layouts), at a smaller scale. Also, the data set should provide enough documents for each layout (40 - 50). - Quality:
This characteristic has two aspects:- First, the tagged data set should not contain any tagging mistakes — any mistakes produced by a selection of incorrect values or in an incorrect fashion.
- The second aspect is the OCR quality of the documents, which should be at maximum possible OCR quality. For information on OCR quality see OCR Analysis and OCR Tuning Guide.
- Structuredness:
The data set should be well-ordered and easy to manage. As a rule, this is achieved by splitting the data set into batches, usually sorted by suppliers and layouts.
Stages of data set collection
There are five stages of the data set collection:
- Analysis:
At this stage, the analysis of the input documents is done. DA estimates document quality and distribution. Then, DA and SME review the set of fields, and together, they align on tagging logic. Later, DA provides a tagging instruction that includes all the rules and corner cases and reflects this alignment. Tagging instructions contain information about business and tagging logic: what should be tagged as correct answers, what's the most important, and where directly in the document it should be tagged. Such instruction should be maintained during tagging and validation. - Preparation & OCR:
DA needs all documents in different formats to be converted into HOCR or HTML format. Usually, documents are digitized from PDF or image format and converted into HOCR/HTML format with the help of the OCR tool Tesseract. It takes documents in PDF format as input and releases the same documents in HOCR/HTML format as output. All input documents should meet the required formats (PDF, PNG, JPEG, HTML or TXT). For image-based files (PDF, PNG, JPEG) verify OCR quality and readability, optimize OCR settings if needed to maximize text recognition accuracy, address any scanning artifacts or quality issues. For information on OCR quality see OCR Analysis and OCR Tuning Guide. - Training SMEs:
Training is dedicated to acquiring the necessary skills to tag documents quickly and effectively. Data Analyst provides a training task to the team of SMEs and gives a presentation on how to tag correctly, then validates the result and provides feedback. - Tagging:
This term can refer to labeling for all types of use cases. But the term tagging is used most often for Information Extraction use cases. This is the process of highlighting all the available fields in the batch of documents to supply them for model training. Usually, this is the longest and most important stage of the data set collection. A Human Task, with all the fields that need to be extracted, is created and all the documents are uploaded, and the SME team starts working on them in EasyRPA's application Workspace. - Validation:
When documents are tagged, DA starts validation of the tagged text. The primary purpose is to ensure there are no tagging mistakes nor omitted fields and values are labeled consistently. This stage can start right after tagging begins and quite often the DA and SME team work in parallel. The final output is the data set, which is referred to as Gold Data for model training, which means the model takes all the fields as 100% correct values and then will reproduce them in production. That is why it's so essential to ensure data set quality - because the best ML results can be achieved only on accurately and precisely tagged documents.
Sequence of Data Set Collection Stages: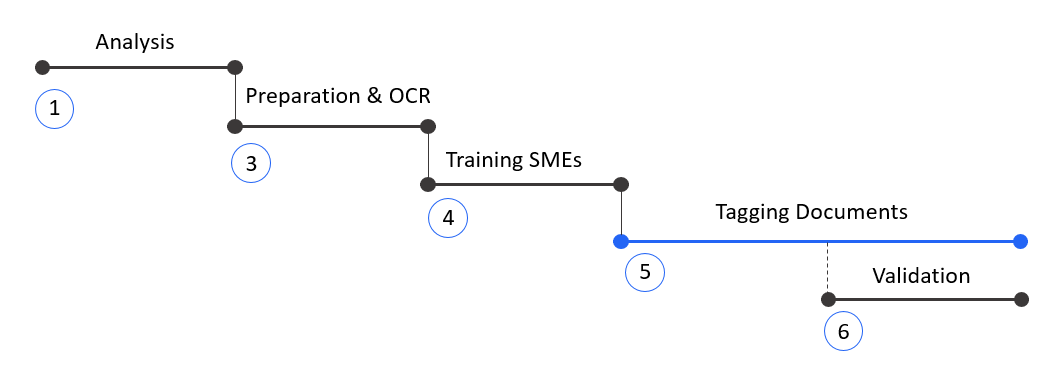
Move Further
Once the dataset is collected, the Data Analyst proceeds to dividing it into two parts: a training set and a test set. The training set is used to train the machine learning (ML) model on annotated or "gold values". In Information Extraction tasks, these gold values refer to specific fields that the model is expected to extract. In Classification tasks, each document is paired with a target class label. The remaining documents of the dataset forms the test set, which comprises unseen documents reserved exclusively for evaluation purposes. This set allows us to assess the model's performance and its ability to handle potential edge cases in a real-world production environment. Importantly, the test set is not used during model training.