Built-in OCR
Built-in OCR
Optical Character Recognition (OCR) in EasyRPA
Optical Character Recognition, commonly referred to as OCR, is the process of converting images of text into machine-readable, editable text data. The EasyRPA platform provides an OCR capability through a dedicated OCR Container. The primary OCR task is to extract text and structural information from documents, which can be either image-based scans or digitally-created PDFs.
This service integrates several open-source technologies to handle different document processing scenarios:
ImageMagick: used as the first step in OCR processing. It splits document by pages, converts them into images and pre-processes images (e.g., deskewing, normalizing) to optimize them for OCR using provided configurations. Results are saved as .jpg or .png files.
Tesseract / PaddleOCR: OCR engines that convert document images into text and HOCR formats and save results.
- Apache PDFBox: A Java PDF library for direct text extraction from digitally-created PDFs, bypassing OCR entirely.
The core task of the OCR Container is to accept a document, apply the appropriate technology pipeline based on configuration, and return structured text and metadata.
Usage Guide: Applying OCR Parameters
When configuring a Document Set, you will need to apply specific parameters to control the OCR pipeline (ImageMagick, Tesseract, PaddleOCR, PDFBox). For a comprehensive guide on all available settings and how to use them, see the EasyRPA Text Extraction Capabilities document.
OCR Modes & Processing Flows
The OCR task supports five primary processing modes, selected via the ocrType parameter in the Document Set settings.
| Mode (ocrType) | Version | Use Case | Key Characteristics |
|---|---|---|---|
| tesseract | 5.5.0 | General-purpose OCR on scanned document images and digitally-created pdfs | Uses Tesseract engine. Processes image files (JPG, PNG, TIFF) or converts PDFs to images for high-quality OCR. Highly configurable. Requires ImageMagick preprocessing. |
| paddleocr | 3.2.0 | General-purpose OCR on scanned document images and digitally-created pdfs | Also requires image input. Uses PaddleOCR engine. Better performance for certain layouts. Requires ImageMagick preprocessing. |
| paddleocrToTable | 3.2.0 | Custom OCR on scanned document images that contain tables (EXPERIMENTAL) | Also requires image input. Uses PaddleOCR’s ability to detect and reconstruct table structures, exporting results as HTML and/or Excel files. Requires ImageMagick preprocessing. See Optical Character Recognition Sample Process (OCR Sample) for more details. |
| pdfbox | 3.0.5 | Text extraction from digitally-created pdfs. Not an OCR engine. | Directly extracts text from PDFs that already contain selectable text layers. Preferable for digitally-created PDFs as it avoids potential character recognition errors. No ImageMagick or OCR needed. |
| converter | - | Document conversion from one format to another. Not an OCR engine. | Converts input documents (XLS, XLSX, ODS, DOC, DOCX, ODT, RTF) with LibreOffice usually to HTML/PDF for further processing, supported formats can be found here and here. No ImageMagick or OCR needed. |
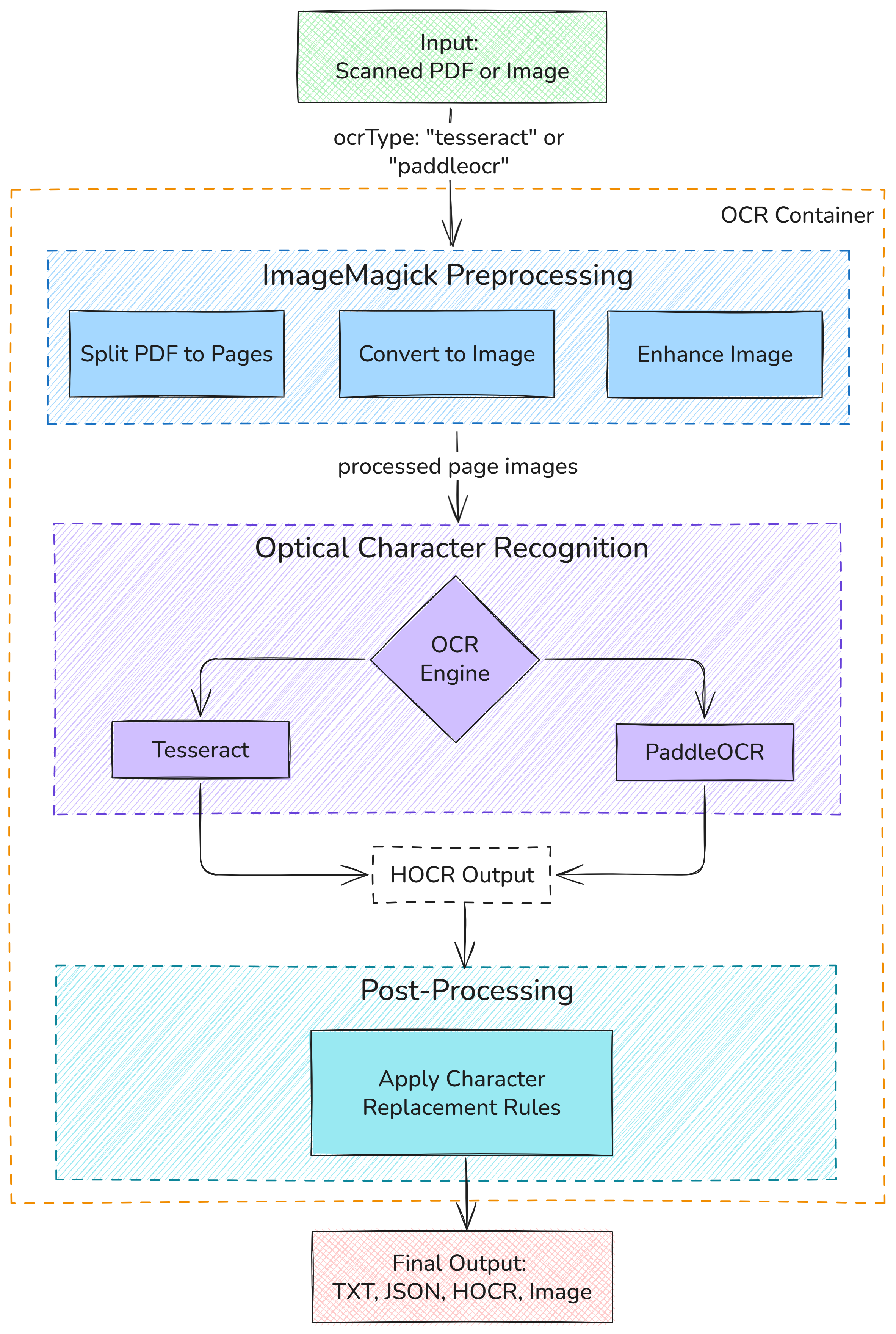
1. Flow for tesseract and paddleocr Modes (Image-based OCR)
This flow is designed for scanned documents and images. It requires the ImageMagick preprocessing stage to prepare content for the OCR engine.
- Input: Scanned PDFs, JPGs, PNGs, and TIFFs.
- Output: Structured text in formats such as JSON, HOCR, TXT and image file(s).
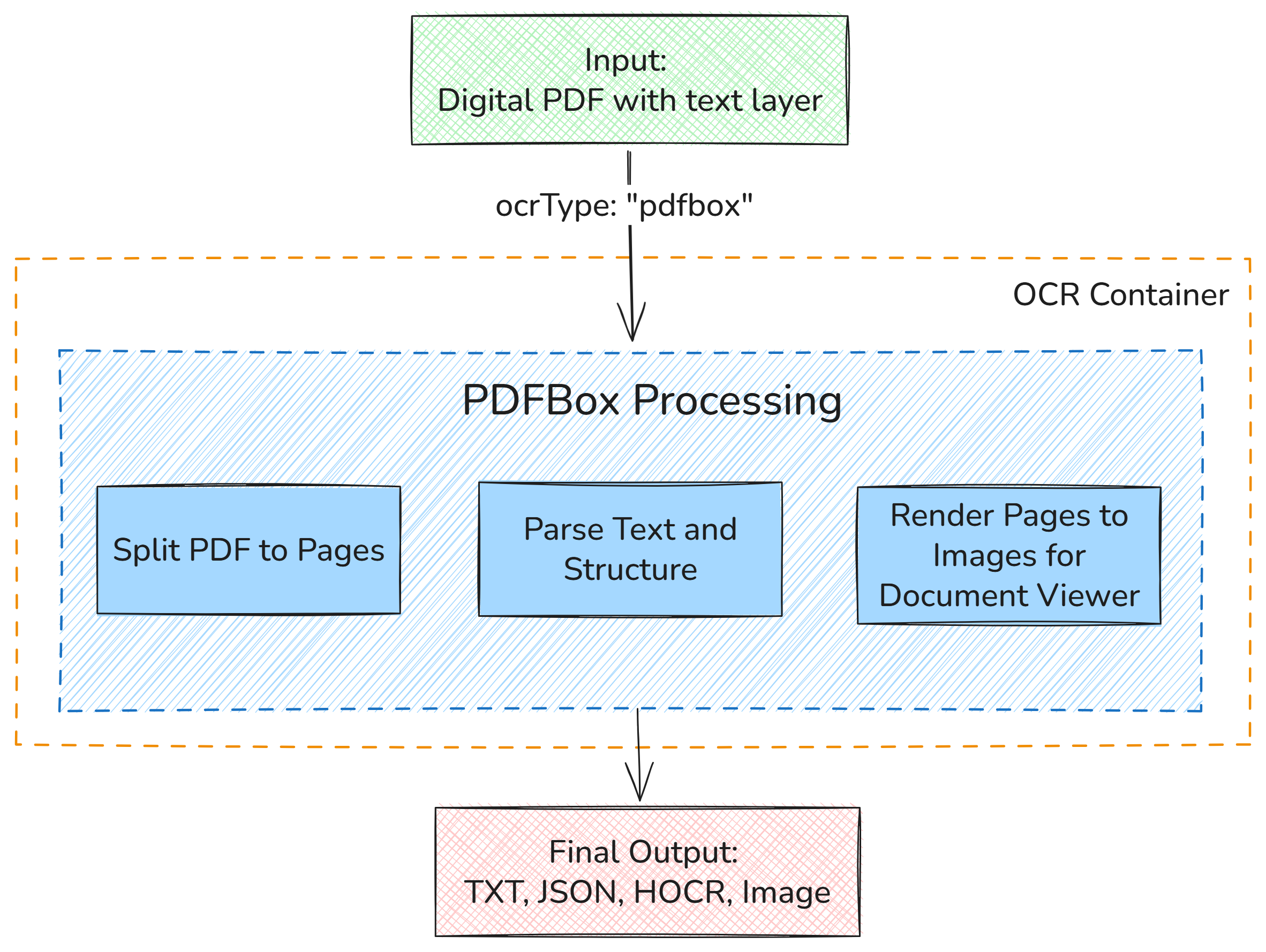
2. Flow for pdfbox Mode (Direct Text Extraction)
This flow is designed for digitally-created PDFs. It bypasses ImageMagick and OCR entirely by extracting the text layer directly.
- Input: Digitally-created PDFs with selectable text layers.
- Output: Structured text in formats such as JSON, HOCR, TXT and image file(s).
The ImageMagick Stage
The key difference between pdfbox or convert and the other modes (tesseract, paddleocr) is the requirement for image preprocessing.
- The tesseract and paddleocr modes rely on ImageMagick for preprocessing, converting source documents into optimized images for the OCR engines to analyze. ImageMagick is the first step in this pipeline.
- The pdfbox mode bypasses this stage entirely, as it extracts text directly from a PDF's text layer. Image rendering is handled internally by PDFBox at a DPI specified by
pdfBoxDpiparameter. ImageMagick is not involved. - The convert mode also bypasses this stage entirely, as it just converts document from one format to another.
Image Processing Operations
ImageMagick splits a PDF into individual pages and renders each page as a high-resolution image (JPG or PNG).
It applies enhancements to images which can improve OCR accuracy. Common operations include:
- -density / -resample: sets the resolution (DPI) of the output image.
- -deskew: automatically straightens a crooked scan.
- -normalize & -contrast: improves contrast and brightness to distinguish text from background.
- -background white: ensures the background is solid white.
- -alpha remove: removes any transparency or color noise.
The specific command-line options used are defined in the imageMagickOptions parameter within the Document Set JSON settings.
To read more about the ImageMagick image processing capabilities, see OCR Tuning Guide.
ImageMagick Scripts
There is also a range of image processing scripts based on ImageMagick functions. They contain sets of ImageMagick parameters that are specifically created to enhance the quality of scanned documents:
- textcleaner: designed to optimize scanned documents by refining the text and eliminating any unwanted background elements. See Textcleaner script.
- otsuthresh: automatically determines the optimal threshold value for converting a grayscale or color image to black and white. See Otsuthresh script.
- unperspective: automatically detects and rectifies perspective distortion in document images. See Unperspective script.
- smarttrim: automatically identifies and trims an image around the region of highest detail or significance. See Smarttrim script.
A sequential execution of image processing scripts is allowed, where each subsequent script utilizes the output file of the previous script as its input. This enables a cascading effect, where multiple scripts can be applied in a specific order to enhance the image quality.
If a script fails to produce an output file during execution, the input file of that script is passed on to the subsequent steps, a corresponding log message is generated.
When running multiple instances of the same script in succession, it is important to create separate exemplars of the script under different names within the same directory. Each exemplar should be assigned a unique name to avoid conflicts. The settings should then be updated accordingly to reference the specific names of each exemplar in the sequential order they are intended to run.
To use ImageMagick scripts the script bucket, script name as well as script configuration options should be specified in the Document Set JSON settings.
OCR Post Processor
After the OCR engine (Tesseract or PaddleOCR) completes text recognition, the results can be further refined by the HocrPostProcessor.
Process developer may optionally provide a configuration that specifies pairs of recognized and correct words. The HocrPostProcessor component goes over HOCR words, replaces all words matching recognized pattern with the corresponding correct word. This component is valuable for correcting common, predictable OCR errors (e.g., correcting "c1erk" to "clerk").
A configuration file defines pairs of recognized patterns and their correct replacements. The HocrPostProcessor scans the HOCR output from the OCR engine. It identifies and replaces words matching the "recognized" patterns with the "correct" word while preserving the original structure and layout of the HOCR file. This corrected HOCR file is then used for generating the final JSON output.
OCR Settings Description
Configuration is done within the Document Set's JSON settings. Below is an example of options.
{
"bucket": "data",
"ocrType": "tesseract",
"imageMagickOptions": [
"-units", "PixelsPerInch",
"-density", "320", // Render source at high resolution
"${source}", // Path to the input file placeholder
"-background", "white",
"-alpha", "remove", // Remove transparency
"-deskew", "40%", // Auto-straighten the image
"-normalize", // Improve contrast
"-quality", "100",
"-resample", "320" // Output resolution for OCR
],
"pdfBoxDpi": 320,
"tesseractOptions": [
"-l", "eng", // Language: English
"--psm", "12", // Page Segmentation Mode: Sparse text
"--oem", "3", // OCR Engine Mode: Default
"--dpi", "320" // Inform Tesseract of the image DPI
],
"paddleOcrOptions": [
"--lang", "en" // Language: English
]
}Here are all supported options:
| key | type | default value | description |
|---|---|---|---|
| bucket | string | data | Specify document storage bucket |
| ocrImageType | string | jpg | The image type (extension) to use in ImageMagick as image type result (jpg, png). |
| tesseractOptions | array of string | "-l", "eng", "--psm", "3", "--oem", "3", "--dpi", "180" | Tesseract command line to use. Only used if ocrType: "tesseract". |
| imageMagickOptions | array of string | "-units", "PixelsPerInch", "-density", "180", "${source}", "-background", "white", "-alpha", "remove", "-deskew", "40%", "-quality", "100", "-resample", "180" | ImageMagic command line to use. Ignored if ocrType: "pdfbox". Converts and enhances source document into images for OCR. |
| paddleOcrOptions | array of string | "--lang", "en" | Paddle ocr command line to use. Only used if ocrType: "paddleocr" |
paddleOcrSoftWordWrap | boolean | false | Switches off paddleocr word recognition from word wrap mode (the --return_word_box flag) into software mode. For some languages (models) the --return_word_box doesn't work, in this case the software bbox calculation will helps workers for tagging. |
| pdfBoxDpi | number | 180 | DPI for rendering page images for the viewer (does not affect text extraction). |
| pdfBoxWordSeparationGapPt | double | 6.0 | Searchable pdf contains lines of text, the OCR converter spits the lines on words using whitespace and space between symbols. The parameter specifies the maximum point between symbols to split line on words. |
| gsPdfPageSplitter | boolean | false | This flag switches document convertation into pages from ImageMagic to GhostScript. |
| gsDpi | number | 180 | DPI for rendering images for GhostScript pdf split. |
| imagePostprocessScriptsBucket | string | rpaplatform/scripts | ImageMagick scripts bucket, see ImageMagick Scripts. |
| imagePostprocessScripts | map of strings | {} | ImageMagick scripts configuration, see ImageMagick Scripts. |
| hocrFixWords | map of strings | {} | OCR Postprocessor configuration, pairs of regexp and correct words. See OCR Post Processor. |
| debug | array of string | [] | Switch on OCR debug options:
|
| ocrType | string | tesseract | Specify the OCR mode: "tesseract", "paddleocr", "paddleocrToTable", "pdfbox" or "converter" |
Usage in a Document Set
To enable OCR for a Document Set, you must define the ocrType and any desired engine-specific parameters in Document Set Details Settings section.
Example 1: Process scanned PDFs with Tesseract:
{
"ocrType": "tesseract",
"imageMagickOptions": [
"-density",
"300",
"${source}",
"-deskew",
"40%",
"-resample",
"300"
],
"tesseractOptions": [
"-l",
"eng",
"--dpi",
"300"
]
}Example 2: Process scanned PDFs with PaddleOCR:
{
"ocrType": "paddleocr",
"imageMagickOptions": [
"-density",
"250",
"${source}",
"-resample",
"250"
],
"paddleOcrOptions": [
"--lang",
"en"
]
}Example 3: Process digital PDFs with PDFBox:
{
"ocrType": "pdfbox",
"pdfBoxDpi": 200
}Auto OCR feature
If its no obvious which OCR engine to be used for an input document, the Auto OCR feature ( ocrType is set to "auto_ocr ") can be used. It will let you select best OCR processing mode based on the input document (either file name or content) and the given rules (JavaScript predicate functions).
- To quick-select OCR processing mode based on a document file name, provide file-name rules in the configuration.
- For auto-selecting OCR engine for a PDF input document, provide complex pdf-analysis rules in the configuration, any input non-pdf format will be auto-converted to a PDF document using LibreOfficeConverter before the rule executed.
For details see information below.
Auto-selecting best OCR processing mode
Process developer have to provide a configuration that specifies :
- How to auto-detect best OCR processing mode with the rules (see example below)
Note
Rules are executed sequentially - from top to bottom until the first match. The rules left will be ignored. So make sure simple file-name rules go first in the list to avoid costly pdf analysis for some of the filenames/extensions.
Note
Rules should be written in JavaScript and should finally return boolean value.
- file-name rules must accept single string parameter - fileName
- pdf-analysis rules may accept multiple numeric parameters:
- average text density per page - avgTextDensity
- average text amount per page - avgTextPerPage
- average image coverage per page - avgImageCoverage
- total images on all pages - totalImages
2. Which OCR processing mode is to use and its parameters (see example below). The parameters provided will overwrite default parameters.
Below is a an example of full auto_ocr config:
OCR Container Details
Input
OCR container expects JSON message as input. Example:
Output
OCR container returns list of OcrOutput objects (one per page), which are filled depending on the input "format" parameter.
- image - image path and image dimension will be returned
- text - path to the text file extracted by the OCR engine
- hocr - path to the postprocessed HOCR file (HTML-based representation of OCR results with positioning data).
- pocr - path to the paddle ocr result json.
- json - returns a JSON structure converted from the HOCR file using HocrJsonConverter
- html - path to the html document converted from the source document
- xlsx - path to the xlsx document converted from the source document
- pdf - path to the pdf document converted from the source document
Some OCR modes support only subset of the OCR formats:
| Mode (ocrType) | Formats |
|---|---|
| tesseract | image, text, hocr, json |
| paddleocr | image, text, hocr, json, pocr |
| paddleocrToTable | image, text, hocr, json, pocr, html, xlsx |
| pdfbox | image, text, hocr, json |
| converter | html, xlsx, pdf |
To explore the OCR image processing pipeline and test available options, see Optical Character Recognition Sample Process (OCR Sample).
For more information about OCR tools and recommended settings, please refer to EasyRPA Text Extraction Capabilities.
To read more about techniques of OCR quality analysis and improvement, see OCR Tuning Guide.