Optical Character Recognition Sample Process (OCR Sample)
Optical Character Recognition Sample Process (OCR Sample)
Overview
The OCR Sample is designed to test and demonstrate a variety of document processing and image preprocessing techniques used to prepare documents for Optical Character Recognition.
The sample allows to explore such techniques as image deskewing, rotation, resizing, perspective correction, noise reduction, contrast enhancement, and other ImageMagick-based preprocessing operations. These adjustments significantly improve OCR accuracy, ensuring that text within images or scanned documents is recognized as precisely as possible.
Beyond image-based preparation, the updated OCR Sample includes demo document sets that demonstrate multi-format document conversion, OCR pipeline automation, and advanced extraction capabilities:
- LibreOffice to HTML: Demonstrates converting input documents of different formats (XLS, XLSX, ODS, DOC, DOCX, ODT, RTF) to HTML for further processing.
- LibreOffice to PDF: Demonstrates converting input documents of different formats (XLS, XLSX, ODS, DOC, DOCX, ODT, RTF) to PDF for further processing.
- Ghostscript + PaddleOCR: Demonstrates preprocessing documents with Ghostscript (DPI assignment and page splitting) and performing OCR with PaddleOCR.
- PaddleOCR to Table: Demonstrates PaddleOCR’s ability to detect and reconstruct table structures, exporting results as HTML and/or Excel files per page.
- PDFBox: Demonstrates direct text extraction from readable PDF documents without performing OCR when the text layer is available.
- Auto OCR: Demonstrates a fully automated OCR service capable of analyzing incoming PDF files to determine their content type (text-based, image-based, or hybrid) and dynamically routing them through the most efficient OCR pipeline using PDFBox, ImageMagick, Ghostscript, PaddleOCR, or Tesseract.
All these capabilities allow users to explore and compare different OCR workflows, adjust script parameters, and observe the impact of preprocessing, format conversion, and automated routing on OCR quality and performance.
Prerequisites
In order to successfully set up and run OCR Sample:
- Ensure that you have a running node with the "AP_RUN" and "SELENIUM" capabilities.
- Upload the OCR Sample package to the Control Server. The package can be found in the following directory: http://<CS host>/nexus/repository/rpaplatform/eu/ibagroup/samples/ap/easy-rpa-ocr-ap/<EasyRPA version>/easy-rpa-ocr-ap-<EasyRA version>-bin.zip
The source code can be found here: https://code.easyrpa.eu/easyrpa/easy-rpa-samples/-/tree/dev/easy-rpa-ml-aps/easy-rpa-ocr-ap - To run the demo "Preprocess" option needs to be launched on a selected document set of the package.
OCR Sample Package Structure
| Folder | Type | Description |
|---|---|---|
| Document Processor | Automation Process | Standard document processing automation process |
| LIBREOFFICE_TO_HTML_SAMPLE_DOCSET | Document Set | Contains documents and document set settings to demonstrate converting input documents (XLS, XLSX, ODS, DOC, DOCX, ODT, RTF) to HTML using LibreOffice. |
| LIBREOFFICE_TO_PDF_SAMPLE_DOCSET | Document Set | Contains documents and document set settings to demonstrate converting input documents (XLS, XLSX, ODS, DOC, DOCX, ODT, RTF) to PDF using LibreOffice. |
| GS_PADDLEOCR_SAMPLE_DOCSET | Document Set | Demonstrates processing documents (assign DPI and split to pages) with Ghostscript, then performing OCR with PaddleOCR. |
| PADDLEOCR_TO_TABLE | Document Set | Demonstrates PaddleOCR’s ability to extract table structure layout and output HTML and/or Excel results per page. |
| PDFBOX_SAMPLE_DOCSET | Document Set | Demonstrates processing readable documents directly via PDFBox for text extraction. |
| AUTO_OCR | Document Set | Demonstrates the AUTO OCR service for automatically analyzing incoming PDFs and routing them through the optimal OCR pipeline. |
| OCR_SAMPLE_TEXTCLEANER | Document Set | Contains documents and document set settings to demonstrate textcleaner script execution results. |
| OCR_SAMPLE_UNPERSPECTIVE | Document Set | Contains documents and document set settings to demonstrate otsuthresh and unperspective scripts execution results. |
| MULTIFORMAT_HTML | Document Type | Information Extraction Document Type |
| MULTIFORMAT_PDF | Document Type | Information Extraction Document Type |
| OCR_SAMPLE | Document Type | Information Extraction Document Type |
| OCR_SAMPLE_TEXTCLEANER | Document Type | Information Extraction Document Type |
| storage/data | Storage | Provides image preprocesing scripts. |
LIBREOFFICE_TO_HTML_SAMPLE_DOCSET
Purpose: Convert input office documents (XLS, XLSX, ODS, DOC, DOCX, ODT, RTF) to HTML using LibreOffice. The process does not require specific document processing JSON settings.
LIBREOFFICE_TO_HTML results example
Input RTF Document Example:
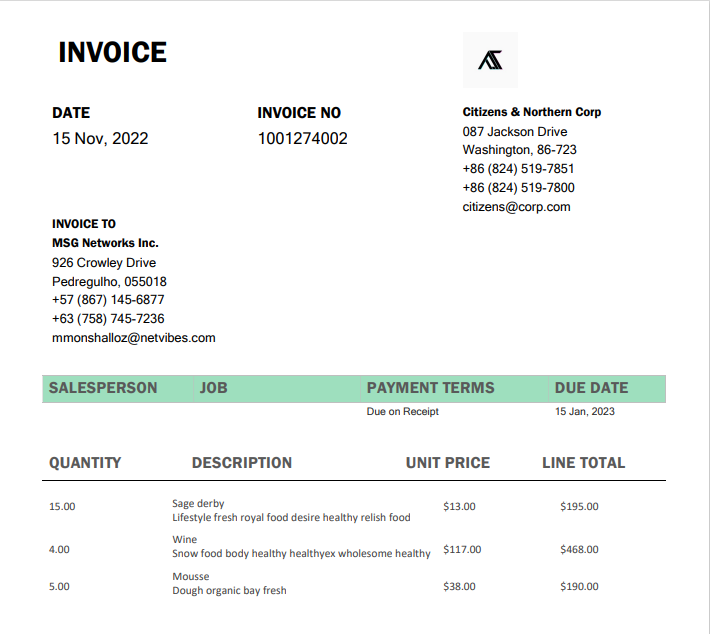
Output HTML Example:

Output PDF Document Example:
LIBREOFFICE_TO_PDF_SAMPLE_DOCSET
Purpose: Convert input office documents (XLS, XLSX, ODS, DOC, DOCX, ODT, RTF) to PDF using LibreOffice. The process does not require specific document processing JSON settings.
Input DOC Document Example:
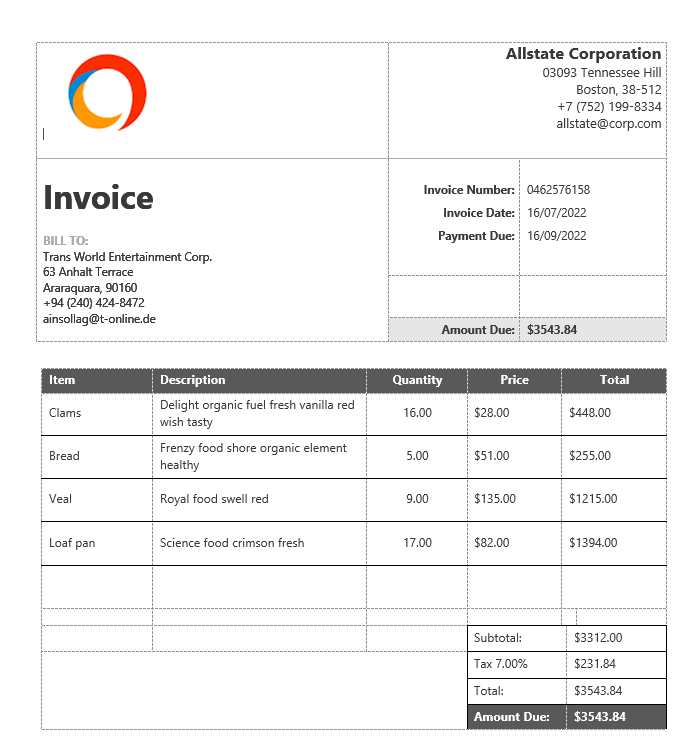
Output PDF Document Example:
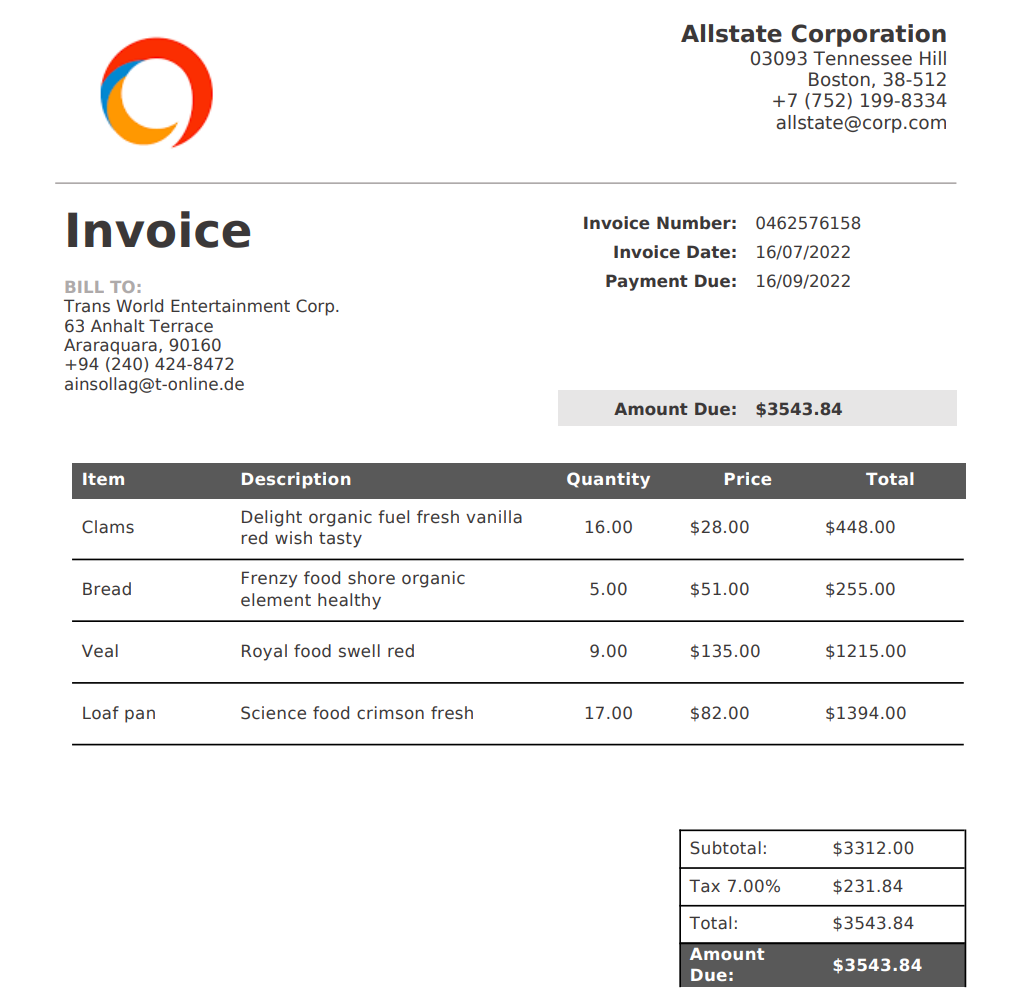
GS_PADDLEOCR_SAMPLE_DOCSET
Purpose: Demonstrates document processing with Ghostscript and OCR with PaddleOCR.
GHOSTSCRIPT+ PADDLEOCR JSON Settings
Below you can find an example of JSON settings provided in the GS_PADDLEOCR_SAMPLE_DOCSET Document Set Details:
GHOSTSCRIPT+ PADDLEOCR JSON settings contain:
- "ocrType": "paddleocr" - Specifies the OCR mode paddleocr"
- "gsPdfPageSplitter": true - This flag switches document convertation into pages from ImageMagic to GhostScript.
- "gsDpi": 270 - DPI for rendering images for GhostScript pdf split.
- "paddleOcrOptions":
- "--lang", "en" - Sets the language for OCR recognition to English
- "--text_det_unclip_ratio", "0.8" - Sets how much to expand text detection boxes
- "--use_doc_unwarping", "false" - Disables document unwarping correction
Input PDF Document:
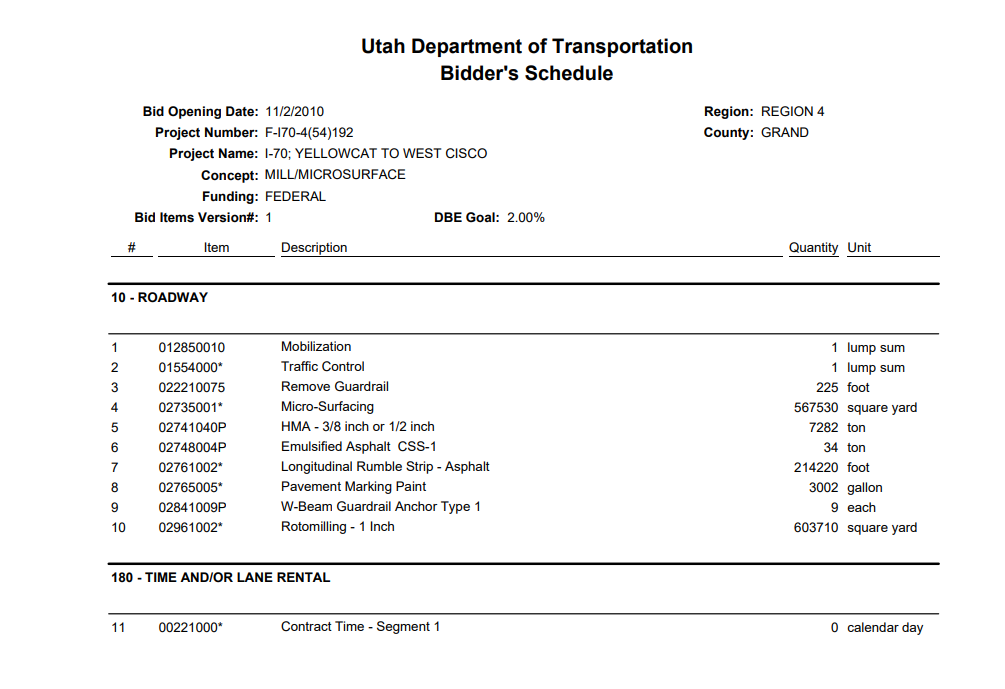
Output GHOSTSCRIPT+ PADDLEOCR result:

PADDLEOCR_TO_TABLE
Purpose: Demonstrates the capability of PaddleOCR to detect and extract table structures from scanned or image-based documents, generating structured HTML and Excel output per page.
PADDLEOCR_TO_TABLE JSON Settings
Below you can find an example of JSON settings provided in the PADDLEOCR_TO_TABLE Document Set Details:
GHOSTSCRIPT+ PADDLEOCR JSON settings contain:
- "ocrType": "paddleocrToTable" - Specifies the OCR mode paddleocr"
- "paddleOcrSoftWordWrap": true - Switches off paddleocr word recognition from word wrap mode (the --return_word_box flag) into software mode. For some languages (models) the --return_word_box doesn't work, in this case the software bbox calculation will helps workers for tagging.
- "gsPdfPageSplitter": true - This flag switches document convertation into pages from ImageMagic to GhostScript.
- "gsDpi": 200 - DPI for rendering images for GhostScript pdf split.
- "ocrImageType": "jpg" - Converts documents to JPG format for processing.
- "paddleocrToTable":
- "cellTolerance": 10 - Pixel tolerance for cell boundaries.
- "wordTolerance": 10 - Pixel tolerance for word grouping.
- "rowClusterTol": 10 - Groups text into rows within 10px vertical distance.
- "colClusterTol": 10 - Groups text into columns within 10px horizontal distance.
- "coverTol": 5 - Tolerance for detecting cell coverage/merging.
- "minCellSize": 30 - Sets the minimum cell size.
- "scaleFactorCol": 45000 - Column width calculation factor
- "scaleFactorRow": 54 - Row height calculation factor
- "cellMergeStrategy": "sentencesBased" - Merges cells based on semantic content rather than just position.
- "tableExporter": "SimpleHtmlExporter,SimpleExcelExporter"
- "paddleOcrOptions":
- "--lang", "en" - Sets the language for OCR recognition to English
- "--text_det_unclip_ratio", "0.9" - Sets how much to expand text detection boxes
- "--use_doc_unwarping", "false" - Disables document unwarping correction
Input PDF Document:
Output HTML table rendering result (part):
PDFBOX_SAMPLE_DOCSET
Purpose: Demonstrates processing of readable or text-based PDF documents using PDFBox for direct text extraction, bypassing image-based OCR when possible.
PDFBOX JSON Settings
Below you can find an example of JSON settings provided in the PDFBOX_SAMPLE_DOCSET Document Set Details:
Input readable PDF Document:

Output PDFBox result:

AUTO_OCR
Purpose:
The AUTO OCR document set demonstrates an intelligent, rules-based OCR workflow that automatically analyzes incoming files to determine their content type and selects the most appropriate processing engine. The system evaluates file characteristics such as text density, image coverage, number of images, and pages analyzed, as well as the file extension, to determine whether a document is text-based, image-based, hybrid, or belongs to a specific format category (JPG, TXT, XLSX, DOCX).
The AUTO OCR configuration uses a set of detection rules followed by engine-specific configurations to ensure that each document type is routed through the most efficient OCR pipeline.
Detection & Routing Logic Based on Rules
AUTO OCR analyzes the specified number of pages of an incoming document and applies the rules in the order listed. Once a rule matches, the corresponding configuration defines how the document is processed.
Here is an example of AUTO OCR JSON settings:
File-Type-Based Routing
These rules are specified before content analysis rules and force a specific engine:
JPG images → processed using Tesseract
TXT files → Converted to PDF with LibreOffice and processed directly with PDFBox (no OCR needed)
XLS/XLSX files → Converted to PDF with LibreOffice and processed with PDFBox
DOC/DOCX files → Converted to PDF with LibreOffice and processed with PDFBox
Content-Based Routing
If the file type does not match the extension rules, AUTO OCR evaluates document content characteristics:
Path 1 - Text-Based Documents
Condition: avgTextDensity ≥ 0.5 and avgTextPerPage ≥ 100
Action: → Routed to PDFBox (direct text extraction, no OCR)
This path handles readable PDF documents.
Path 2 - Image-Based Documents
Conditions (either one qualifies): avgTextDensity < 0.1 and totalImages > 0, or avgImageCoverage > 0.7 and avgTextPerPage < 100
Action: → Routed to Tesseract OCR (with ImageMagick preprocessing)
This path is optimized for scanned or photo-like documents where OCR is required as well as quality improvement preprocessing.
Path 3 - Hybrid Documents
Condition:
- avgTextDensity ≥ 0.3
- avgImageCoverage > 0.3
- totalImages > 0
Action: → Routed to PaddleOCR with:
- Ghostscript PDF page splitting (gsPdfPageSplitter: true)
- DPI assignment (gsDpi: 180)
This path handles documents containing a mix of readable text, embedded images, charts, or inconsistent page structure.
Default Path
If no rule matches: Routed to PaddleOCR (with Ghostscript preprocessing)
This ensures that any unclassified or unusual document still receives high-quality OCR processing.
Summary of Processing Engines Used
| Scenario | Engine |
|---|---|
| Text-based documents | PDFBox |
| Image-based documents | Tesseract |
| Hybrid documents | PaddleOCR + Ghostscript |
| JPG files | Tesseract |
| TXT / XLS / XLSX / DOC / DOCX | PDFBox |
| Default | PaddleOCR + Ghostscript |
OCR_SAMPLE_TEXTCLEANER Document Set
In this example textcleaner script is run on a set of text documents images to remove noise and clean the text background.
JSON Settings for TEXTCLEANER script
Below you can find an example of JSON settings for TEXTCLEANER script provided in the Document Set Details.
TEXTCLEANER script JSON settings contain:
"imagePostprocessScriptsBucket": "data/ocr_sample/scripts"
- This specifies the directory where the image preprocessing scripts are stored.
"imagePostprocessScripts":
- This section defines the specific image preprocessing scripts and their parameters.
"textcleaner":
- The name of the preprocessing script being utilized.
Parameters for "textcleaner" script:
- "-g": converts the image to grayscale.
- "-e stretch": enables automatic image brightness enhancement.
- "-f 25": sets the filter radius to 25 pixels.
- "-o 15": sets the offset value to 15.
- "-t 30": sets the smoothing threshold value to 30.
- "-u": applies deskew to the image.
- "-s 1": sets the sharpness amount to 1.
- "-T": enables image trimming.
- "-p 20": sets the border pad amount to 20.
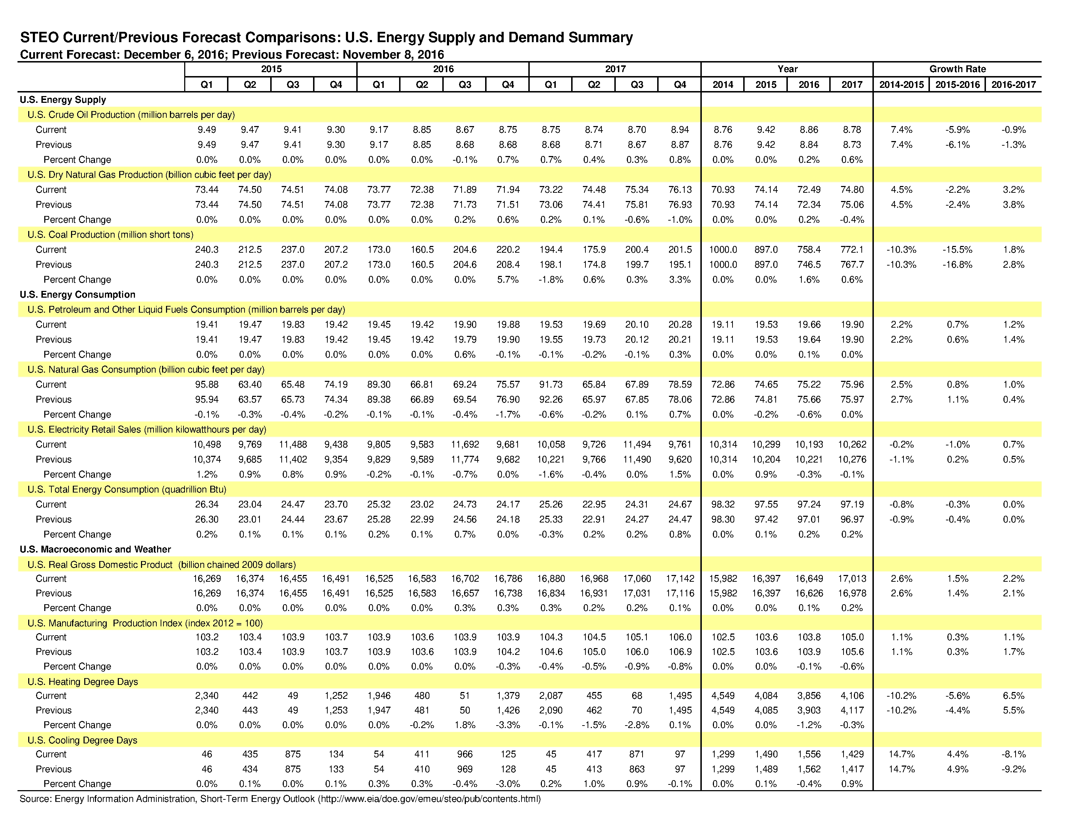
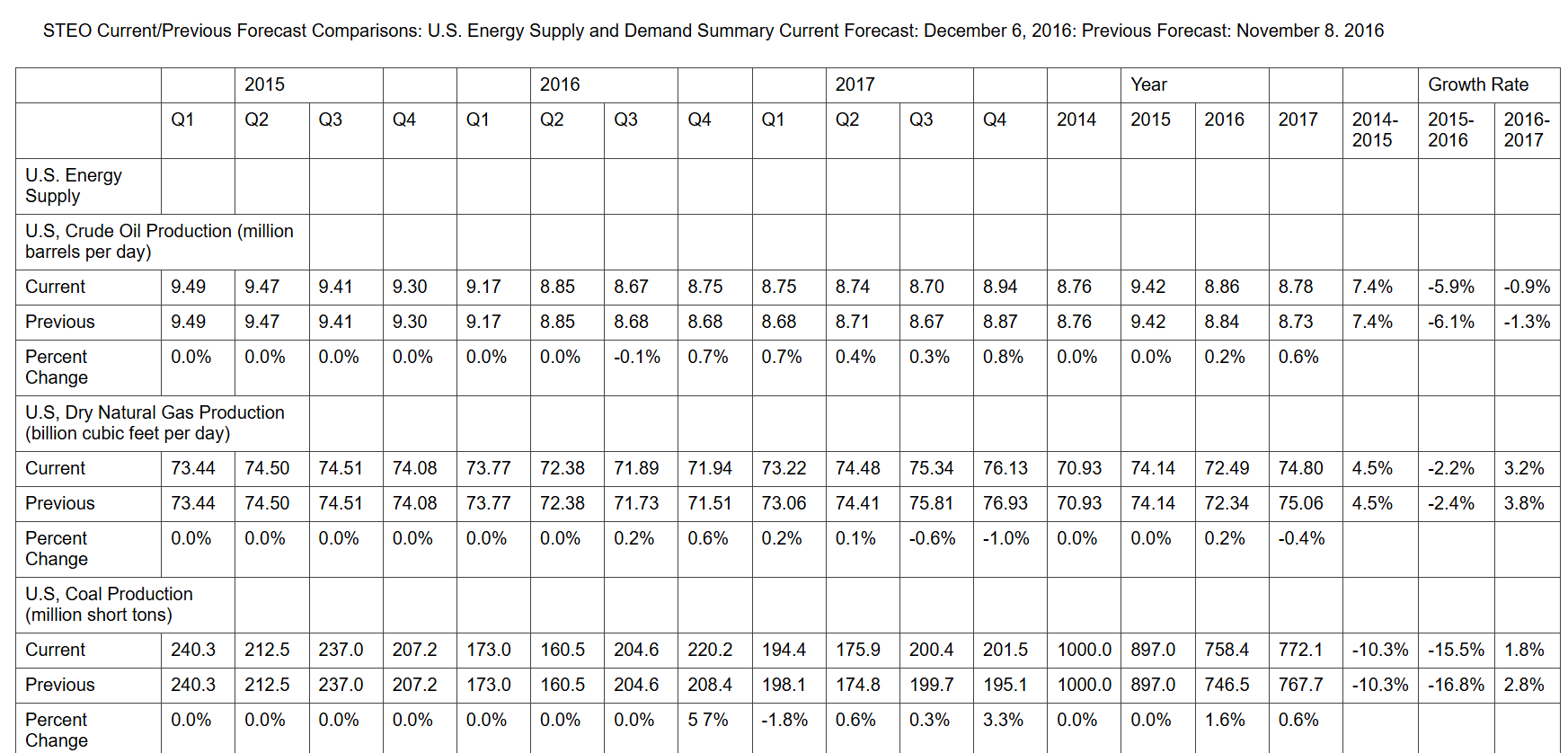
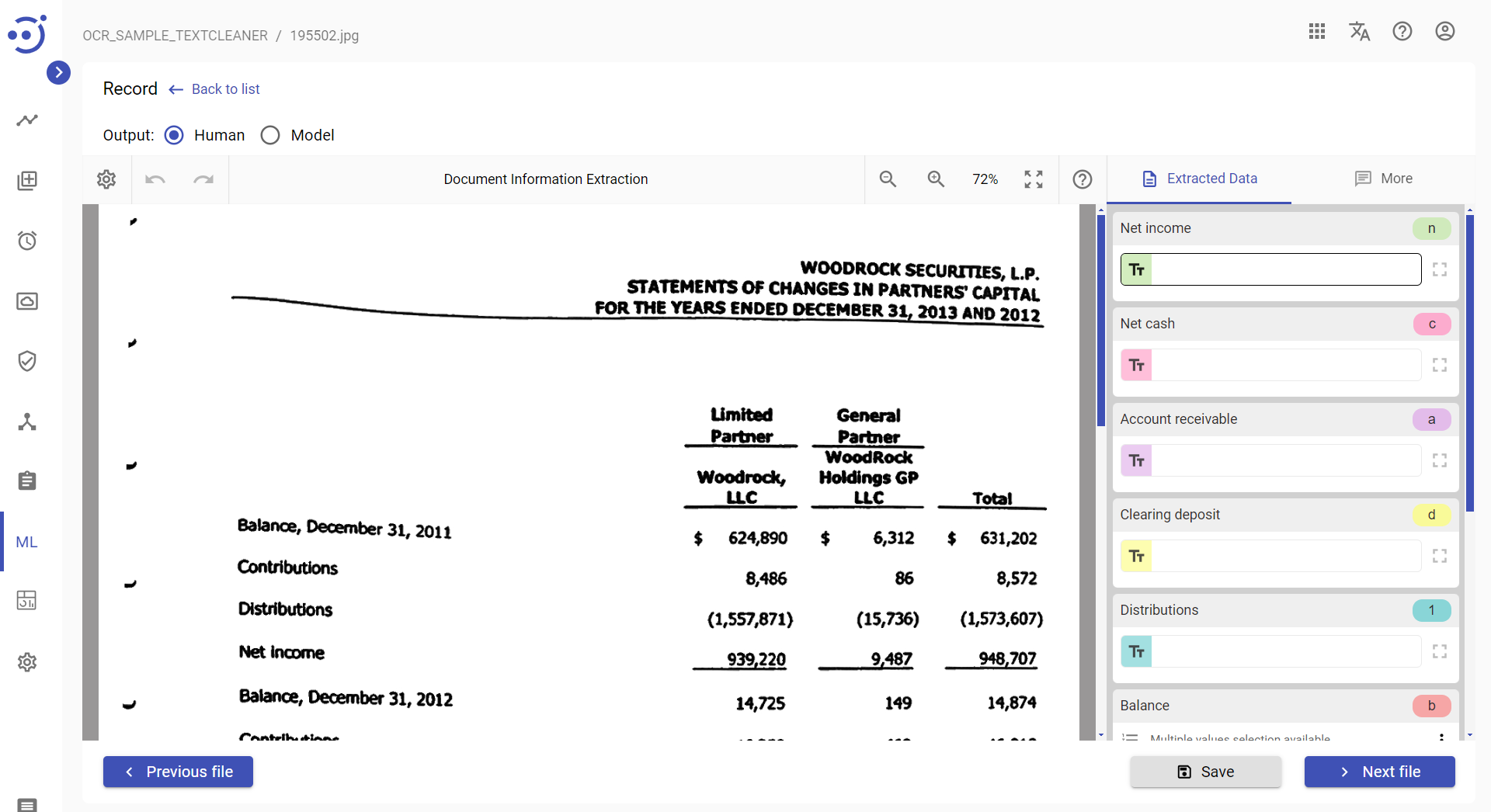
TEXTCLEANER script results example
Example of a document image before TEXTCLEANER script execution:
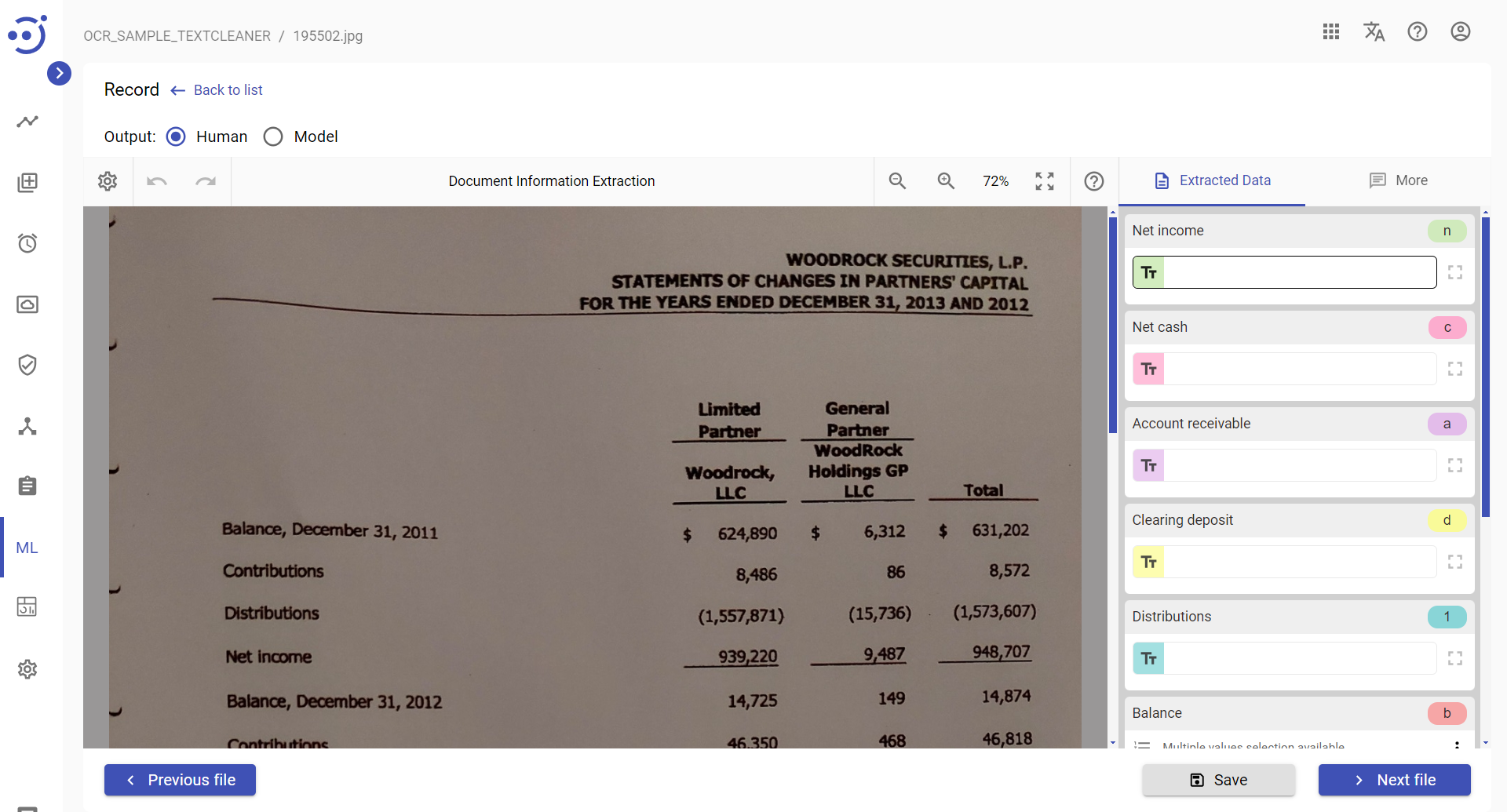
Example of a document image after TEXTCLEANER script execution:
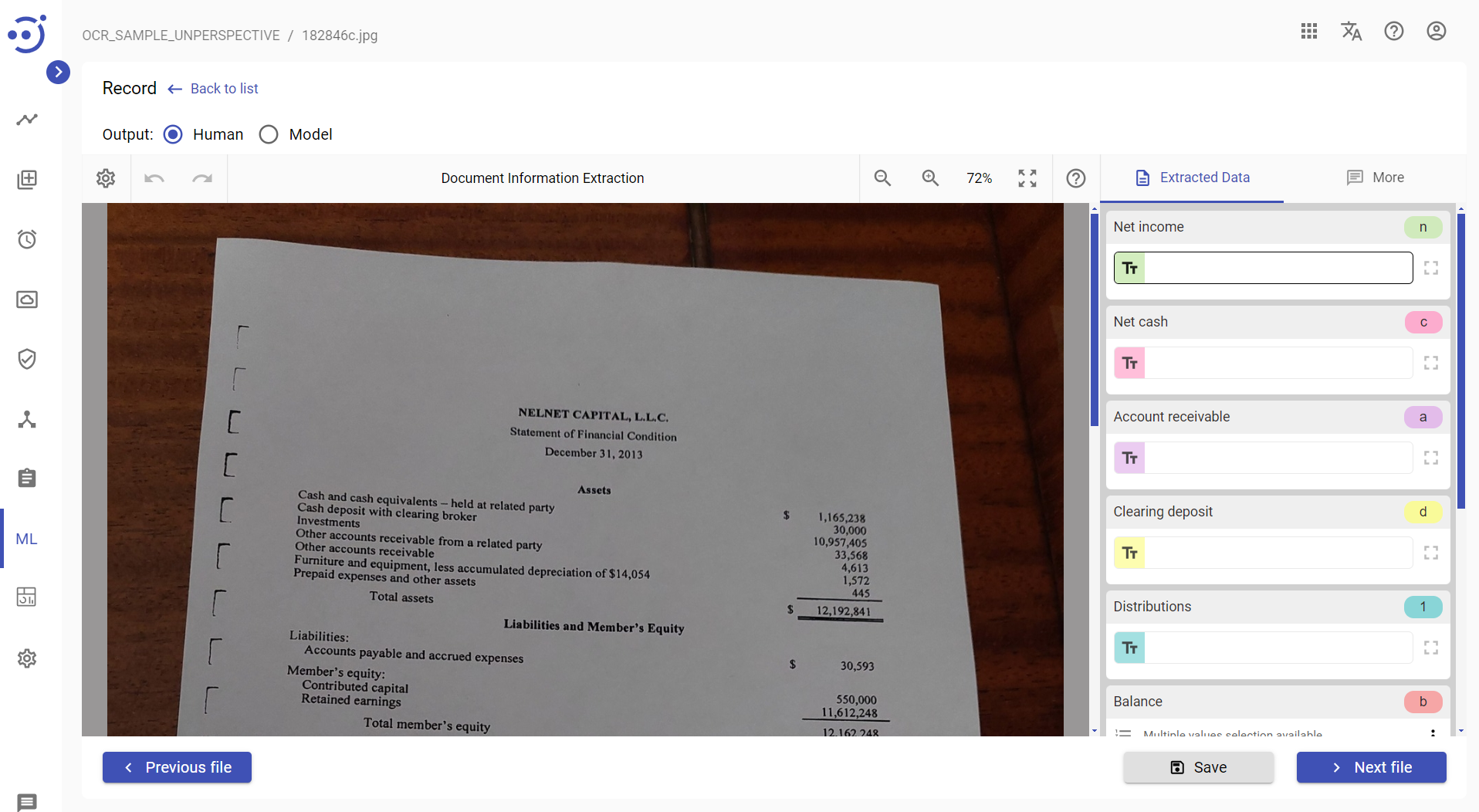
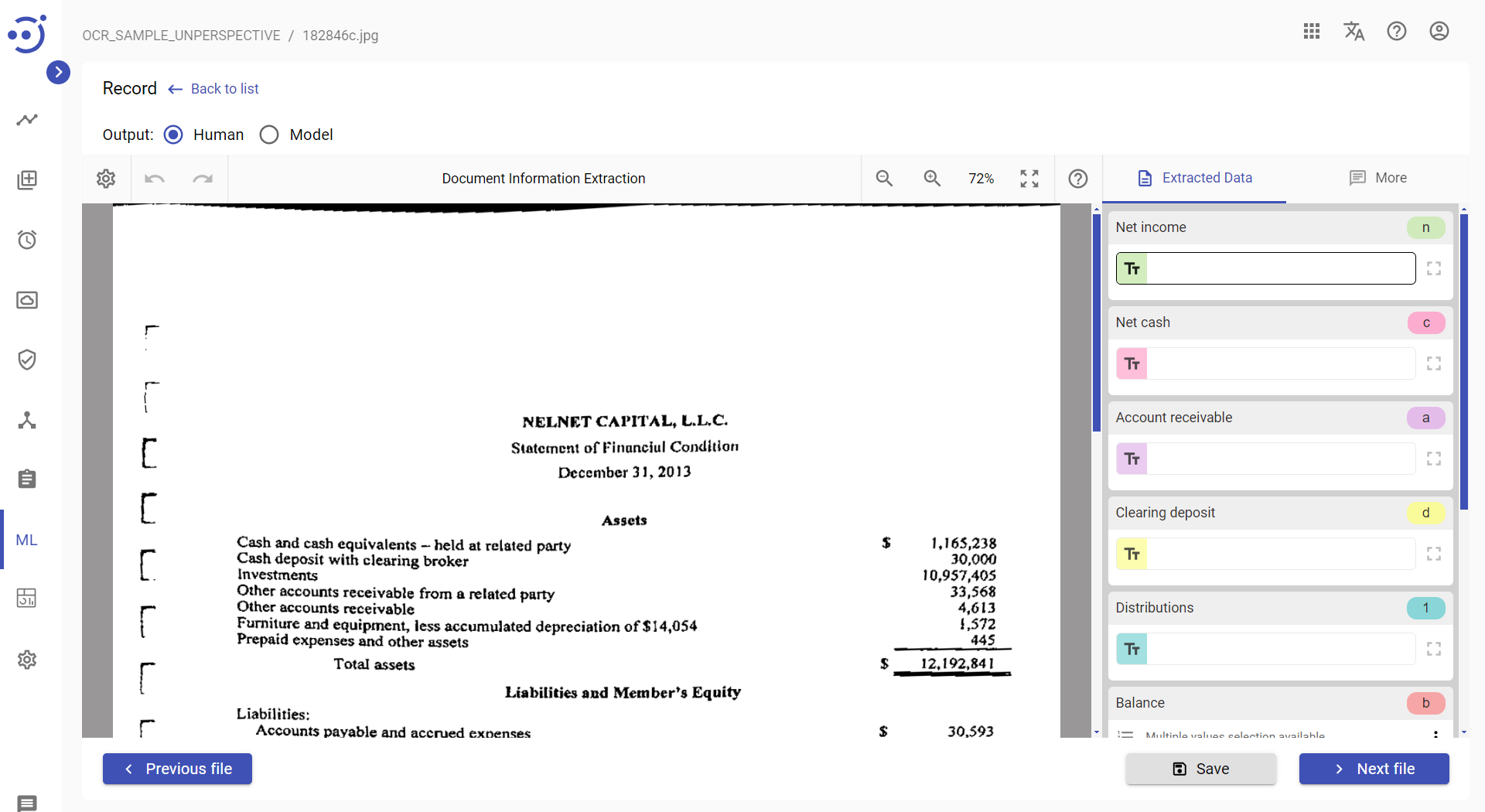
OCR_SAMPLE_UNPERSPECTIVE Document Set
In this example a sequence of otsuthresh and unperspective scripts is run on a set of document images to remove pespective distortions.
JSON Settings for OTSUTHRESH and UNPERSPECTIVE scripts
Below you can find an example of JSON settings for OTSUTHRESH and UNPERSPECTIVE scripts provided in the Document Set Details.
"imagePostprocessScriptsBucket": "data/ocr_sample/scripts"
- This specifies the directory where the image preprocessing scripts are stored.
"imagePostprocessScripts":
- This section defines the specific image preprocessing scripts and their parameters.
"otsuthresh":
- This is the name of the first preprocessing script, which is "otsuthresh."
Parameters for "otsuthresh" script:
- This script is invoked without any additional parameters.
"unperspective":
- This is the name of the second post-processing script, which is "unperspective."
Parameters for "unperspective" script:
- "-C black": sets the background color to black.
- "-i save": saves intermediate images during processing.
- "-A 12": sets the area threshold for connected components filtering to 12 degrees.
- "-s 5": sets the smoothing amount to remove false peaks to 5.
- "-t 10": sets the threshold value for removing false peaks to 10.
- "-B 1": sets the blurring amount to 1.
- "-d h": sets the output dimensions to input image height.
- "-a 0.79": sets the desired width/height aspect ratio to 0.79.
OTSUTHRESH and UNPERSPECTIVE scripts results example
Example of a document image before a sequence of OTSUTHRESH and UNPERSPECTIVE scripts execution:
Example of a document image after a sequence of OTSUTHRESH and UNPERSPECTIVE scripts execution:
To read more about OCR image processing pipeline, see Digitizing Documents (OCR).
To explore the techniques of OCR quality analysis and improvement, see OCR Tuning Guide.