Data Set Requirements
Data Set Requirements
The raw data that data analysts begin with needs to fit a certain profile and will also determine how much data needs to be annotated and prepared for training a model.
Here are some important document set features to remember when collecting data. The document set should be:
Sufficient
There should be enough of data. You need a sufficient amount of data for it to be representative and contain enough mentions of each field or document type. How much is "enough?" That depends on the problem, but more data typically improves the model and its predictive power.
Compare the size of data sets below.
Data set | Size |
151 | |
1,138,562 | |
Amazon reviews | 82,000,000 |
Google Books Ngram | 468,000,000,000 |
As you can see data set sizes differ greatly. The following learning curve shows that the model's performance increases as you add more data to a certain point where the model has saturated and will not benefit from adding more data.
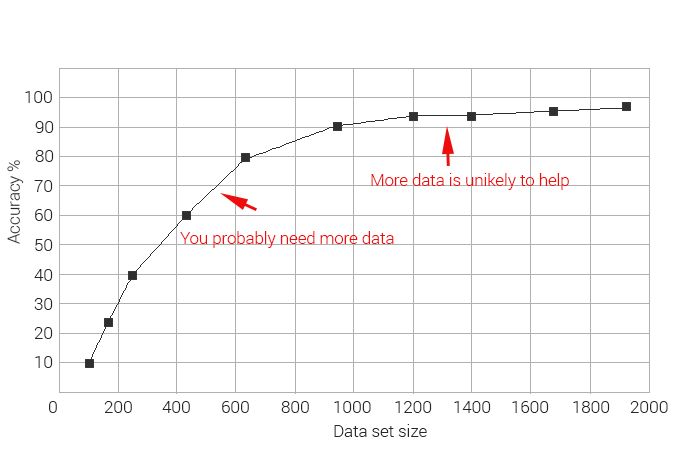
The average size of the data set for basic linear models varies between use cases and depending on the documents complexity and consistency typically numbers from 500 to 1000 documents. This ensures accurate model performance and is crucial to the creation of gold values that are used to train and test the machine learning system. If you have less data available, consider a non-machine learning solution first.
When proceeding with data annotation at a later stage make sure to include enough labelled examples for each category. The bare minimum required for training the information extraction system is 30 examples per label.
Representative
Your data set should cover the domain vocabulary, format, and type of the documents you intend to put for training the machine learning system. The distribution of the document types and layouts should reflect the document flow in production at a smaller scale. For each document type and layout there should be sufficient number of examples.
A representative data set gives the model real world examples similar to what it will be asked to categorize or extract in a production system. You do not necessarily need to train your model on every possible kind of situation a document might be submitted but try to make your data set as representative as possible. This approach will give your machine learning model the best chance of success and let it learn from the widest range of documents available. It will create the best baseline possible as your ML team will continue to refine your model’s performance over time.
Balanced
Your data set should have comparable number of examples of each category that the model is supposed to classify or values that the model is supposed to extract. For example, a model cannot learn to extract a corporate title if there are not enough examples of that particular corporate title in the training data.
When analyzing customer’s documents flow you are likely to come across unbalanced sets of documents where you might have document class A with 90 observations and document class B with 10 observations. The model works best when there are minimum 30 examples of the least common category. Documents that have very low frequency are recommended to remove from the data set and deal with them separately.
High-quality
Data is typically messy and often consists of missing values, useless values, outliers or uncommon examples and so on. There is not much use in having a big representative data set if the data is inaccurate and poor quality. The high-quality data set is the one that allows you to solve your customer’s business problem successfully. In other words, good data allows a data analyst to accomplish his intended task.
The causes for inaccurate data might be different. Erroneous data might arise from:
- errors during documents entry or transmission;
- inappropriate formats of the documents;
- duplication of training examples;
- poor OCR quality due to marks and lines from crumpled or stained paper originals;
- low resolution of OCR documents;
- missed values during data annotation;
- wrong labelled values during data annotation.
Prior to model training and analysis, raw data needs to be cleaned, transformed, and ordered into batches by suppliers or layouts.