Human Task Sample (HT Sample)
Human Task Sample (HT Sample)
Overview
HT Sample performs automatic processing of Form documents such as Quiz, Customer Survey, Article, Financial Report (multiple source documents). The process is designed to generate documents from Data Store input, send them to Workspace for human processing and gather filled by human information into separate Data Store.
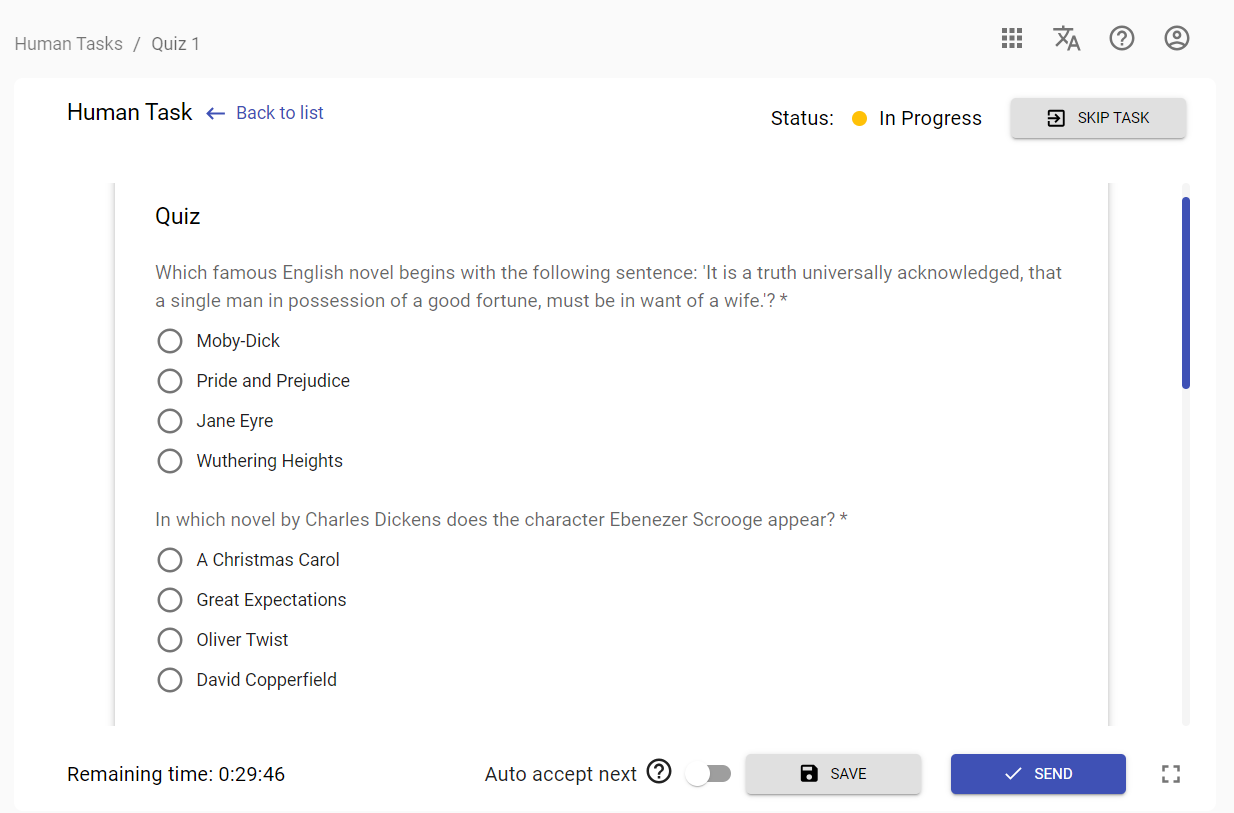
Quiz
In the Quiz user would need to go through set of questions and submit answers through checking appropriate radio boxes.
Example of the Quiz opened in Workspace:
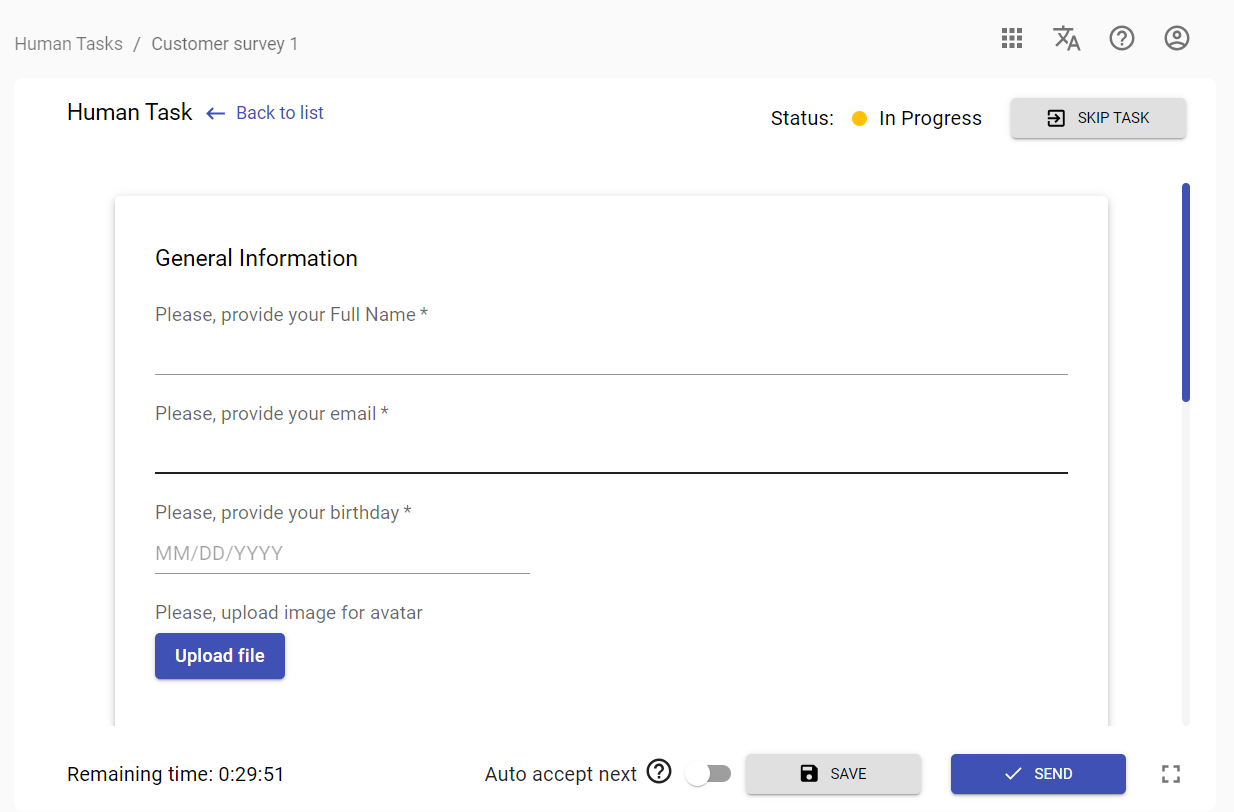
Customer Survey
In the Customer Survey user would need to go through set of input fields and enter personal data like typing name, email or uploading avatar image.
Example of the survey opened in Workspace:
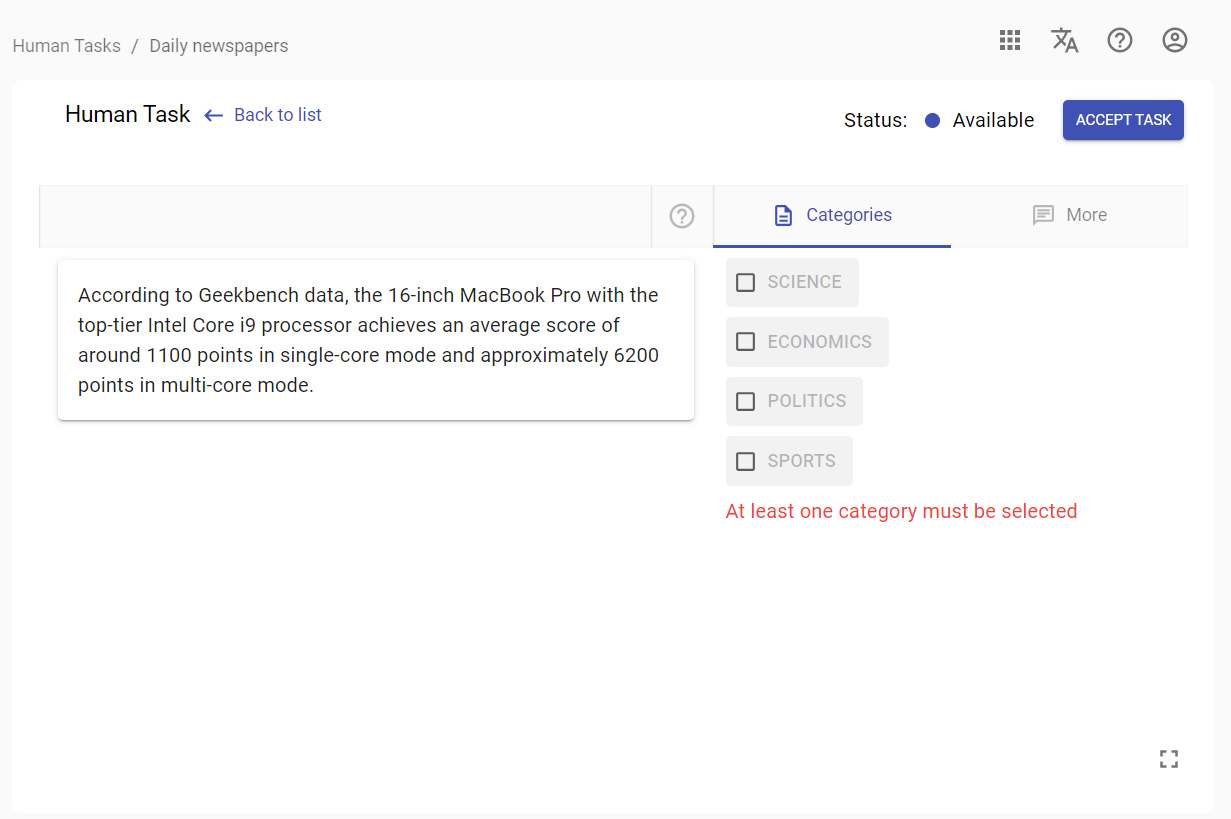
Article
In the Article user would need to do classification of what this article is about. Answer should be submitted by selecting one of the check-boxes provided in the Categories choice.
Example of the Article opened in Workspace:
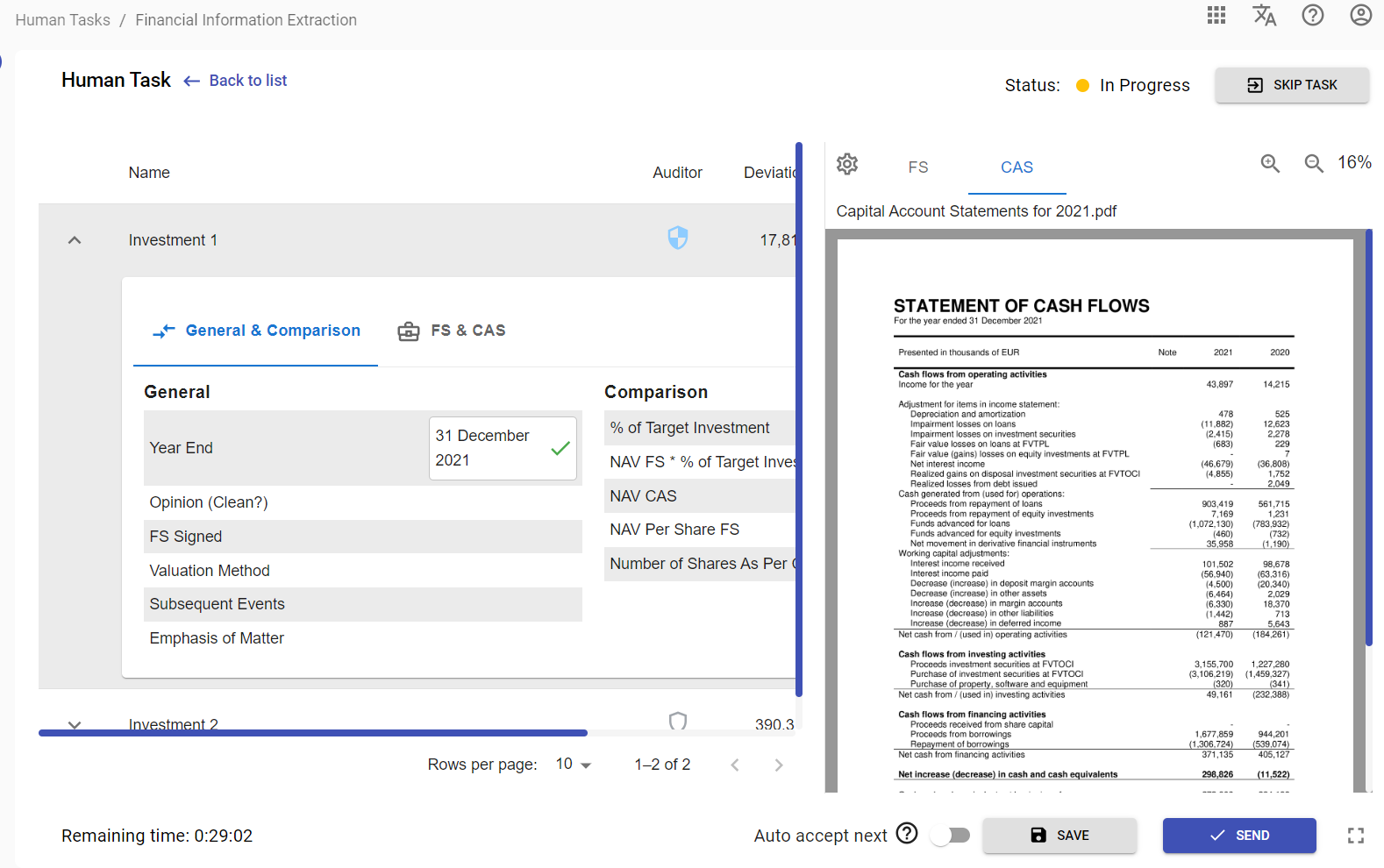
Finance Report (multiple source documents)
In the Finance Report user would need to extract financial data from the multiple sources. Extraction can be done by selecting a report input field (left area) and then mapping a value from a source document tab (right area).
Example of the Finance Report opened in Workspace with the first source document (FS) tab selected:
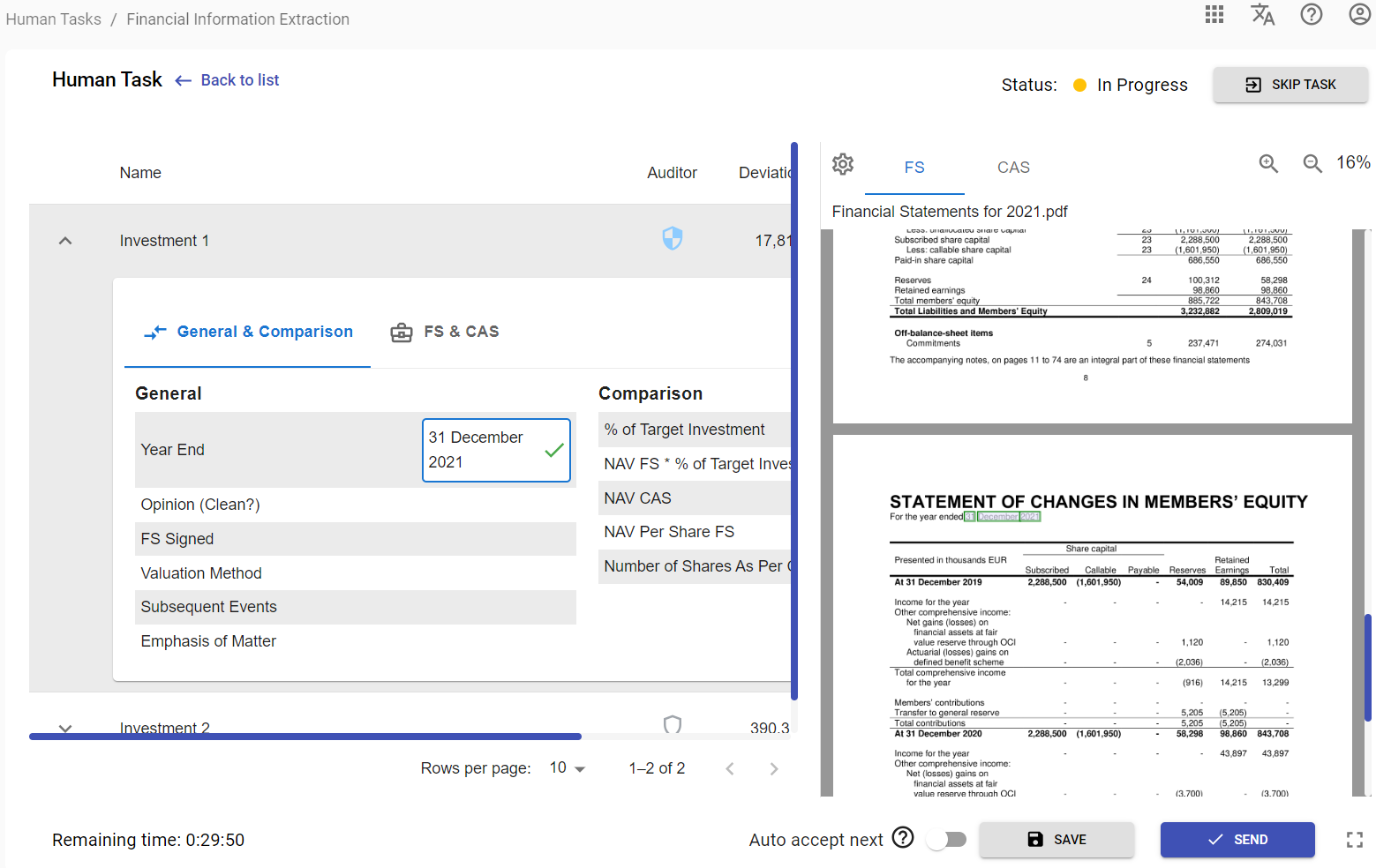
and second source document (CAS) tab selected:
Prerequisites
In order to successfully set up and run HT Sample Process:
Ensure that you have a running node with the "AP_RUN" capability.
Upload the HT Sample package to the Control Server. The package can be found in the following directory: http://<CS host>/nexus/repository/rpaplatform/eu/ibagroup/samples/ap/easy-rpa-ht-ap/<EasyRPA version>/easy-rpa-ht-ap-<EasyRA version>-bin.zip. The souce code: https://code.easyrpa.eu/easyrpa/easy-rpa-samples/-/tree/dev/easy-rpa-ht-ap
Ensure the following details are provided for the HT Sample automation process in the Automation Process Details tab
Module class: eu.ibagroup.sample.ht.HtSample
Group Id: eu.ibagroup.samples.ap
Artifact Id: easy-rpa-ht-ap
Version Id: <EasyRPA version>
HT Sample Process Package structure
Resource | Type | Description |
|---|---|---|
HT Sample | Automation Process | HT Sample automation process |
| HT_SAMPLE_INPUT | Datastore | Data Store that contains an Input for Human Tasks |
HT Sample Articles Classification | Document Type | Classification document type. Defines document categories to be identified |
HT Sample Customer Survey | Document Type | Form document type. Defines document fields to be filled |
| HT Sample Multi Document IE | Document Type | Financial Details document type. Defines document details to be extracted |
HT Sample Quiz | Document Type | Form document type. Defines document fields to be filled |
Classification Task | Human Task Type | Classification human task type. Defines the task input form in the Workspace |
| Form Task | Human Task Type | Form human task type. Defines the task input form in the Workspace |
| IE Multi Doc Task | Human Task Type | Information Extraction human task type that supports multiple source documents. Defines the task input form in the Workspace |
easy-rpa-iehml-ap-<EasyRPA version>.jar | JAR file | Root archive and dependencies. Contains code of HT Sample automation process |
| storage/data | Storage | Provides multiple referenced resources for IE Multi Doc Task HTT |
Data Stores for HT Sample Automation Process:
Name | Columns |
|---|---|
HT_SAMPLE_INPUT | document_type, name, description, priority, task_input, task_output |
HT_SAMPLE_RESULT | document_type, name, description, priority, task_input, task_output |
- document_type - document type to which document belongs
- name - name of the input document which is displayed in Workspace
- description - description of the input document which is displayed in Workspace
- priority - a priority with which the Automation Process will process the Human Task
- task_input - input data for Human Task
- task_output - output data generated as a result of Human Task processing
Included Steps
Step 1. Ingest Documents
RPA bot generates documents from the HT_SAMPLE_INPUT. The data store record of each document contains the initial name of the original document, its description, priority, associated document type, and document input. Please note, that documents with empty task_input are generated from the associated Document type.
After this step, a separate workflow of RPA tasks is created for each document and documents are sent to Workspace for further processing by human.
Step 2. Process Documents
Once human tasks are created it needs to be completed in Workspace. It contains Form input related to four Document types that humans can fill in accordance with Document type validation.
Step 3. Import Processed Data to Data Store
As soon as a human task is completed an RPA task is created to input the extracted data into HT_SAMPLE_RESULT Data Store.
Multi Document Information Extraction Human Task
Document Type JSON Structure
Below you can find an example of the Settings JSON for the Multi Document Information Extraction Task:
These settings contain:
- colors(map) (optional) - overrides highlight colors
- <entityName> (hex color value) - extracted entities with name entityName will be highlighted with this color
Input JSON for processed PDF files
Represents the document's OCR result in JSON format superimposed on the original documents picture. It is generated automatically during OCR preprocessing:
Input JSON contains:
- investments (list of objects) - the root element containing a list of investments data to display
- id (number) - unique id of the investment
- name (string) - name of the investment
- check (boolean) - shows whether there are inconsistencies between Financial Statement and Capital Account Statement documents
- auditor (object) - information about investment auditor
- name (string) - name of the auditor
- trusted (booelan) - shows whether auditor is trusted
- deviation (object) - contains deviation values for extracted data
- abc (number) - result of ABC analysis
- percentage (number) - relative deviation
- fs (object) - result of OCR processing of Financial Statement document
- documentName (string) - name of processed document (filename)
- images (list of objects) - element containing a list of document configurations for every page.
- content (url or base64 string) - the source of the input document to display. It may be an URL to a document or the document's content encoded in base64 (e.g. the string value "data:image/jpg;base64,R0lGOD....").
- json_src or json (http link to a OCR-JSON file or JSON itself) - provides OCR information. OCR-JSON structure is described below.
- dimensions (object) - an object contains "width" and "height" parameters which represent the width and height of the original input document.
- width (integer) - width value of original input document.
height (integer) - height value of original input document.
- cs (object) - result of OCR processing of Capital Account Statement document. Has the same structure as fs property.
- investments (list of objects) - the root element containing a list of investments data to display
OCR-JSON object has the following structure which is generated by the OCR component by itself:
This JSON contains all OCRed words and is kept in a tree-like structure: pages → areas → paragraphs → lines → words
- json (object) - root element
- pages (list of objects) - list of pages structure. Each page in the list has the following structure:
- id (string) - id of the page
- areas (list of objects) - list of areas structure. Each area in the list has the following structure:
- id (string) - id of the area
- paragraphs (list of objects) - list of paragraphs structure. Each paragraph in the list has the following structure:
- id (string) - id of the paragraph
- lines (list of objects) - list of lines structure. Each line in the list has the following structure:
- id (string) - id of the line
- words (list of objects) - list of words structure. Each word in the list has the following structure:
- id (string) - id of the word
- text (string) - original text extracted by OCR engine
- properties (object) - property object with the following structure:
- bbox (list of integers) - top-left and bottom-right coordinates of the rectangle around the word in the original document. Coordinates are normalized to be from 0 to 1 relative to original document size
- x_fsize (integer) - is the OCR-engine specific font size
- x_wconf (integer) - OCR-engine specific confidence for the entire contained substring. Higher values express higher confidence
- pages (list of objects) - list of pages structure. Each page in the list has the following structure:
Output JSON for processed PDF files
As an Output for PDF Information Extraction Human Task produces the following JSON:
It has the following structure:
- entities (map) - root element which contains a list of extracted entities.
- <investmentId> (map) - map of entities extracted for investment with id investmentId
- <entityName> (object) - stores information about entity witn name entityName
- content (string) - final output text of the extracted entity.
- document ("fs" | "cas") - type of document entity was extracted from.
- words (list of objects) - list of word objects. If the extracted text consists of several words, this list will contain several word objects as follows:
- content (string) - original text from the input document.
- bbox (list of integers) - top-left and bottom-right coordinates of the rectangle surrounding the word in the original document. The coordinates are normalized to be from 0 to 1 relative to the original document size.
- id (string) - id of the word.
- page (integer) - original document page number where the word appears.
- <entityName> (object) - stores information about entity witn name entityName
- <investmentId> (map) - map of entities extracted for investment with id investmentId